
AUTOMATIC1111さんが開発している「Stable Diffusion web UI」がめちゃくちゃ凄いのでご紹介します!
これを使えば「文章から画像を生成」や「画像から画像を生成」はもちろんのこと、
- 画像の一部分だけをAIで描き直す
- 上下左右ループしたタイル画像を作る
- AIで人物の顔を補正する
- AIで画像をキレイに拡大
- VRAMが足りない環境でも大きな画像を生成
- 独自の学習データを使用して画像を生成
などなど、現在Stable Diffusionで可能な非常に多くの機能をUIで簡単に利用できる優れもの!
これまでのローカル環境構築と同じくいくつかの事前準備は必要ですが、それ以降のインストールはほとんど自動で行ってくれます。
これからStable Diffusionを始める人も、すでにローカル環境構築済みの人も、ぜひぜひ一度お試し下さい!
2023/01/30 追記:
run.batをダブルクリックするだけで起動できるバイナリが配布されたようです。
https://github.com/AUTOMATIC1111/stable-diffusion-webui/releases/tag/v1.0.0-pre
事前の準備
まずは事前に以下の準備をしておく必要があります。
- Hugging Faceのライセンスに同意
- Pythonのインストール
- Gitのインストール
- CUDAのインストール
上記の準備ができていない場合は、筆者が以前書いた以下の記事を参考に設定してみてください。

Gitのインストールについては別の記事で解説しています。

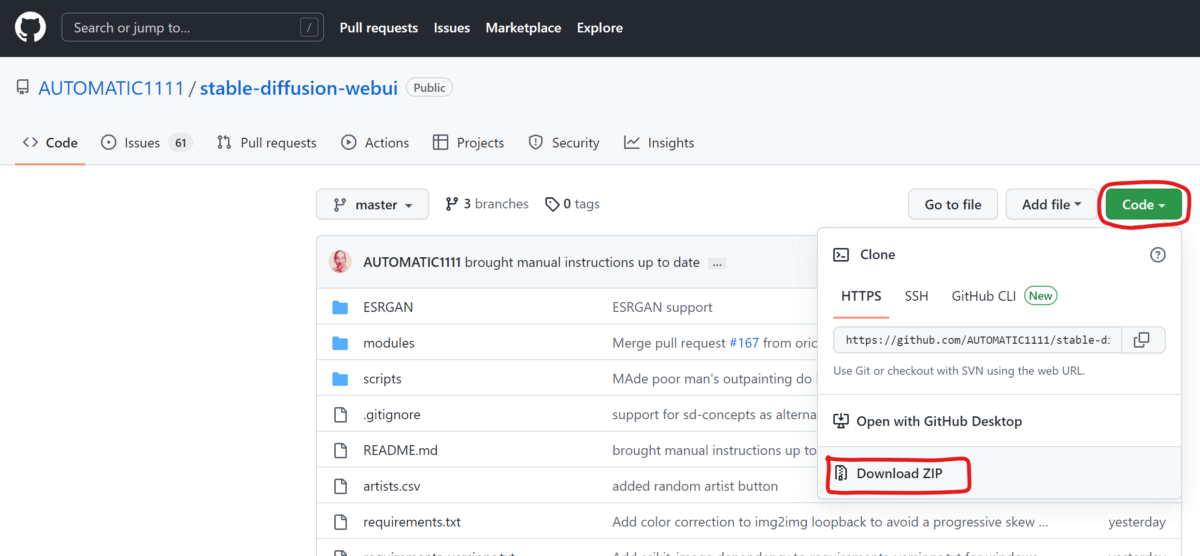
「Stable Diffusion web UI」をダウンロードする
それでは、いよいよ「Stable Diffusion web UI」をインストールしていきましょう。
GitHubのサイト(https://github.com/AUTOMATIC1111/stable-diffusion-webui)にアクセスしてzipファイルをダウンロードして、解凍します。
Hugging Faceからモデルをダウンロードする
Hugging Faceのサイト(https://huggingface.co/CompVis/stable-diffusion-v-1-4-original)にアクセスして「sd-v1-4.ckpt」ファイルをダウンロードしましょう。
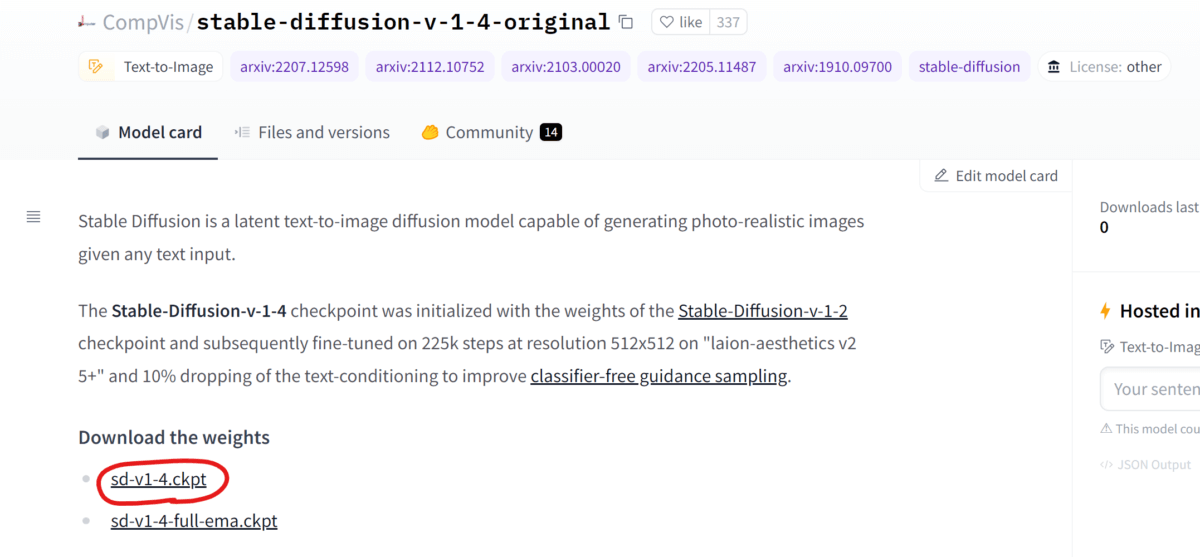
あらかじめライセンスに同意していないとダウンロードページは表示されません
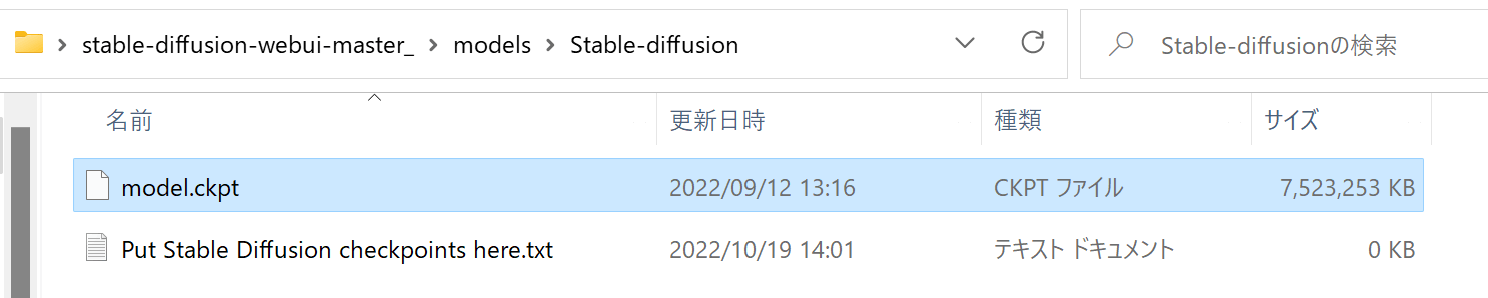
ダウンロードしたファイルの名前を「model.ckpt」に変更してから、先ほど解凍した「stable-diffusion-webui-master」フォルダ内の「models/Stable-diffusion」に移動させます。
「GFPGAN」をダウンロードする
続いて人物や動物の顔を補正する「GFPGAN」をダウンロードします。
GitHubのサイト(https://github.com/TencentARC/GFPGAN)からバージョン1.3をダウンロードしましょう。
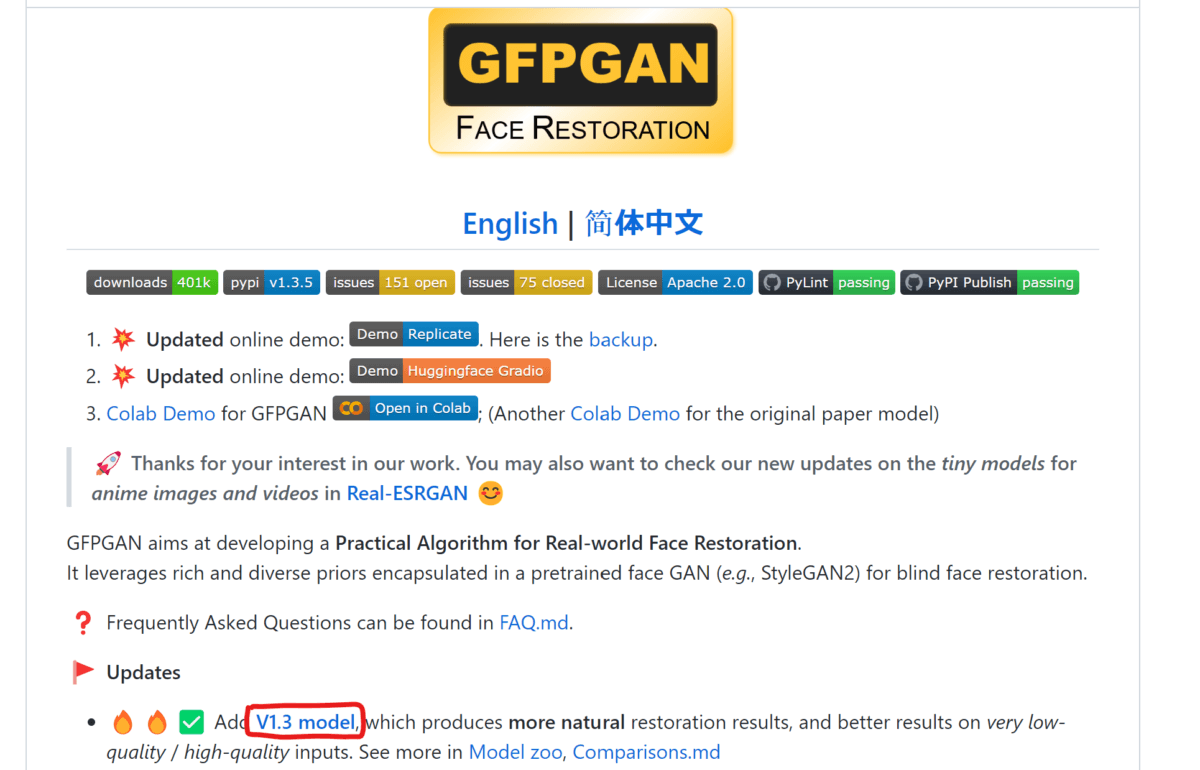
対応するバージョンは「Stable Diffusion web UI」のバージョンによって異なるかもしれません。筆者がアクセスしたタイミングではまだ1.4には対応していませんでした。
ダウンロードしたファイルを、先ほど解凍した「stable-diffusion-webui-master」フォルダに移動させましょう。
「Stable Diffusion web UI」を起動する
同じフォルダにある「webui.bat」をダブルクリックすればコマンドプロンプトが起動し、必要なツールのインストールが始まります。初回はめちゃくちゃ時間がかかると思いますので気長にお待ち下さい。
処理が完了したら、下の方に表示されているURLをコピーしてブラウザに貼り付ます。
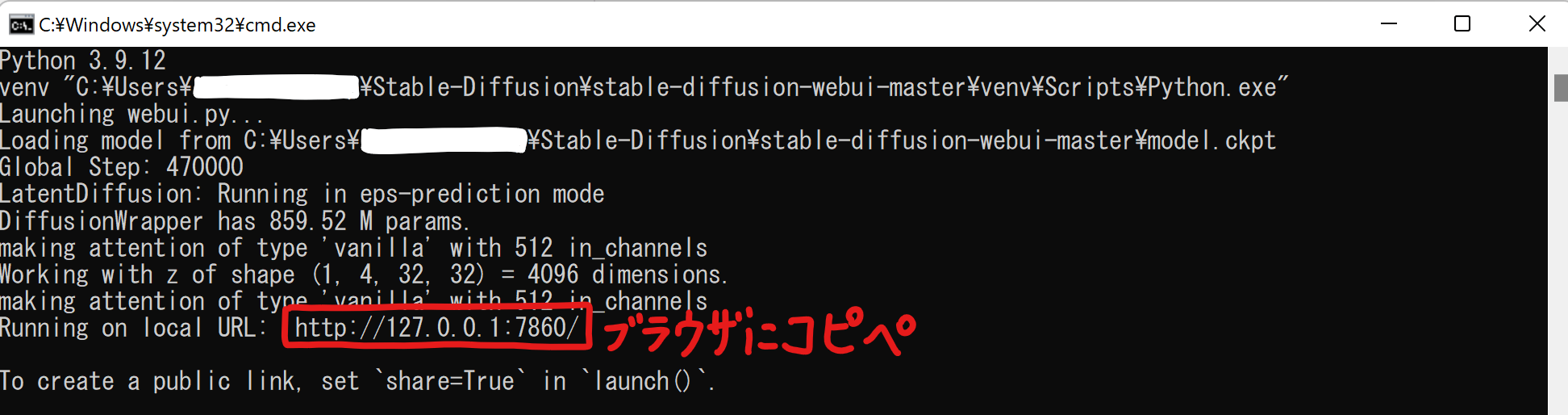
ブラウザで上記のURLにアクセスすると、「Stable Diffusion web UI」が起動します。
途中でコマンドプロンプトを閉じてしまうと画像の生成ができなくなります。「Stable Diffusion web UI」を使い始める際は毎回「webui.bat」を起動してから上記のURLにアクセスしましょう。
文章から画像を生成する「txt2img」の使い方
アプリ上部にいくつかのタブが並んでいます。文章から画像を生成するには一番左の「txt2img」タブを選びましょう。
「Prompt」欄に文章を入力してから「Generate」ボタンを押すと、文章に応じた画像が生成されます。ブラウザで動作しているのでオンラインサービスかと勘違いしてしまいますが、ちゃんとローカルで動いているので爆速ですよ!
生成された画像は「stable-diffusion-webui-master」フォルダ内の「outputs」フォルダに自動的に保存されています。
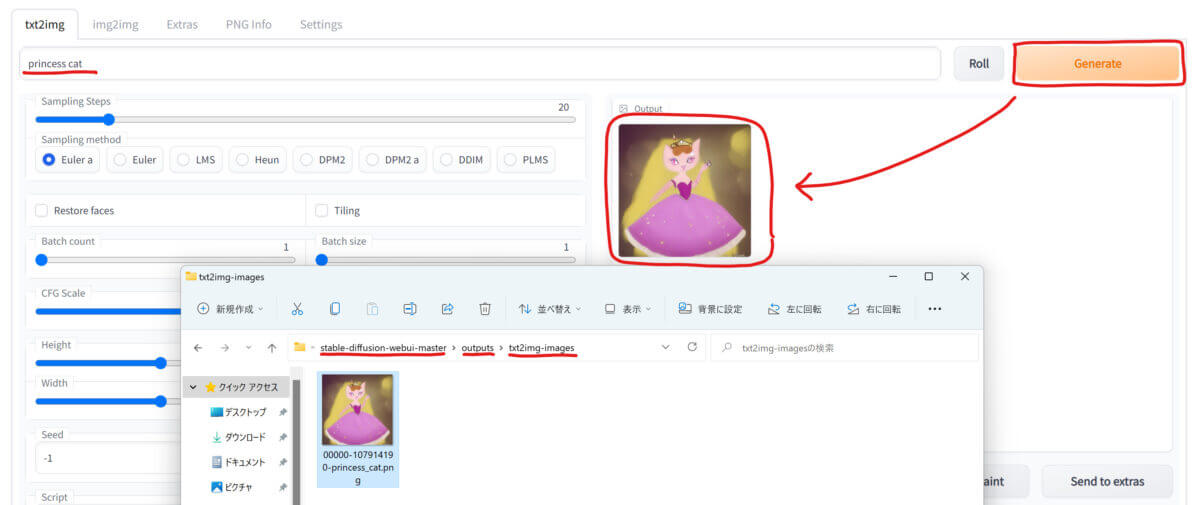
保存された画像のファイル名は「生成番号」「シード値」「プロンプト」の順に並べた文字列です。
以下、「txt2img」で生成される画像を調整するためのパラメータをご紹介します。
シード値を設定する
シード値を設定するには「Seed」パラメータを使います。「-1」を指定するとランダムに値が決定され、任意の値を指定するとシード値を固定できます。

同じ条件、同じシード値で画像を生成すれば全く同じ画像が生成されます。
画像のクオリティを調整する
「Sampling Steps」の値は大きいほど繊細な画像になりますが、画像の生成に時間がかかります。

人物や動物の顔を補正する
「Restore Faces」をONにすると、画像生成後に「GFPGAN」を使って人や動物の顔を補正します。

以下、「Restore Faces」を適用した画像の例です。左が元画像、右が補正済み画像です。

おかしい目や顔のバランスを描画し直してくれますが、処理にはけっこう時間がかかるので、まずは画像のシード値を決めてから仕上げとして使うと良いかもしれません。
タイル画像を作成する
「Tiling」をONにすると、画像の上下左右を繋げるとループするように画像を生成してくれます。

以下の画像は、「Tiling」をONにして生成した画像を4枚並べてみた例です。ゲームのマップを作る時などめちゃくちゃ役立ちそうですね。

生成する画像の枚数を変更する
「Batch size」は1回の処理で何枚の画像を生成するか、「Batch count」は処理を何回行うかを指定する値です。両者を掛け合わせた数の画像が生成される事になります。

「Batch size」値を増やすと使用するVRAMの量が増え、エラーの可能性が高まります。「Batch count」はVRAMの使用量に影響しません。VRAMの多い環境では「Batch size」を増やしても構いませんが、そうでなければ「Batch count」で生成数を調整するのがベターです。
文章から生成される画像の忠実さを調整する
「CFG Scale」は入力した文章(Prompt)にどれだけ近い画像を生成するかを指定できます。値が大きいほど文章に忠実になりますが、絵が安定しなくなる傾向があるようです。まずはデフォルト値で試してみて、徐々に値を変えていくといいんじゃないでしょうか。

画像のサイズを変更する
「Height」と「Width」は画像の高さと幅のサイズです。ピクセル数で指定します。

画像サイズを大きくするとVRAMが足りなくなる場合がありますし、Stable Diffusionはもともと512×512サイズの画像を学習に用いているため、アスペクト比を変えると精度が落ちるという話もありますので、デフォルトのままでいいんじゃないでしょうか。
大きな画像が欲しい時は、後述するAIを使った画像の拡大をすればOKです。
画像から画像を生成する「img2img」の使い方
続いて、左から2番目のタブ「img2img」を使って、既存の画像を元にして新たな画像を生成してみましょう!
まずは元になる画像をドラッグ&ドロップして読み込みます。
そして「txt2img」の時と同じく、「Prompt」欄に文章を入力してから「Generate」ボタンを押すと、元画像と文章に応じた画像が生成されます。
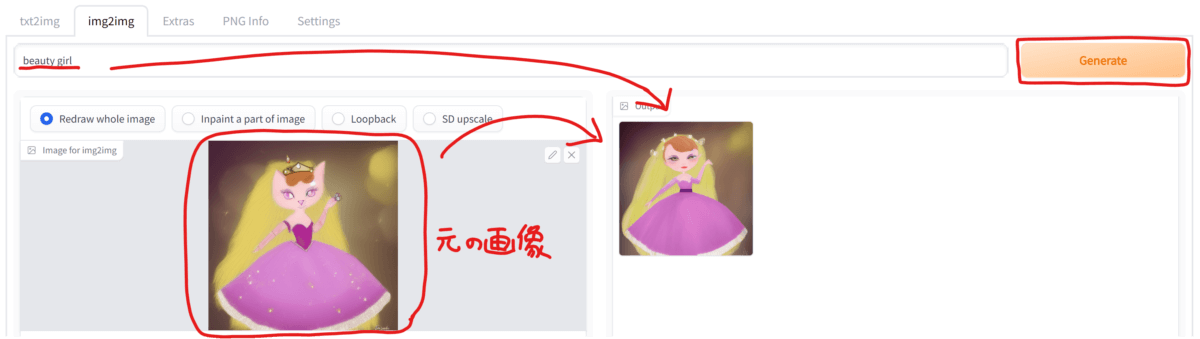
生成された画像は「stable-diffusion-webui-master」フォルダ内の「outputs」フォルダ以下に保存されますが、「txt2img」とは別のフォルダに保存されている事にご注意ください。
パラメータは基本的に「txt2img」と同じですが、「img2img」でのみ有効なパラメータを以下でご紹介します。
元画像と異なるサイズの処理を選択する
元になる画像のサイズと、パラメータで指定したサイズが異なる場合に、生成される画像をどのように処理するかを選択できます。

それぞれどのように処理されるのかは、実際に画像をみた方が分かりやすいので以下をご覧ください。

変化の度合いを調整する
「Denoising strength」の値が大きくなるほど、元画像からの変化の度合いが大きくなります。

「img2img」を繰り返し適用する「Loopback」の使い方
「img2img」で生成した画像を元画像にして、さらに「img2img」を繰り返す「Loopback」という機能があります。
「Loopback」を選択して、先ほどと同じように元画像を読み込んで「Generate」を押すと処理を開始します。
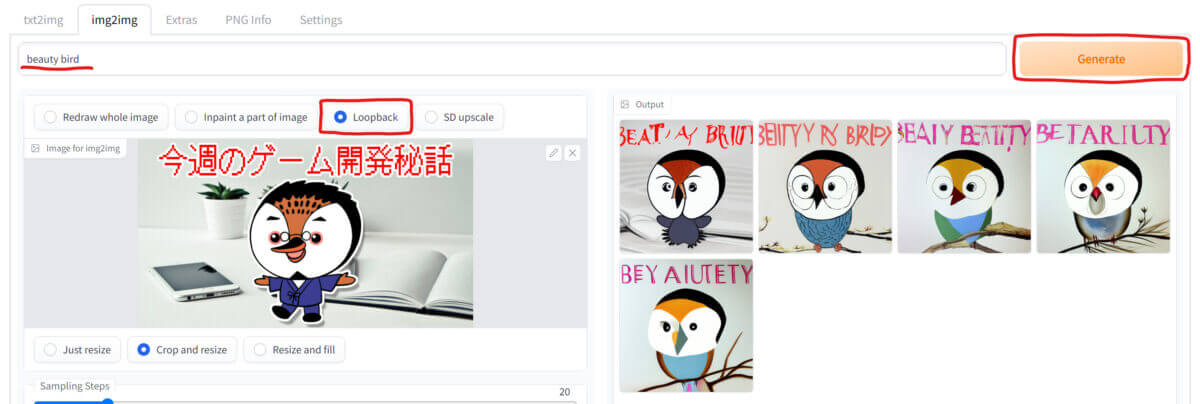
繰り返す回数を指定する
「Batch count」の値を変更して繰り返し処理する回数を指定します。

繰り返す度に変化の度合いを大きくする
処理を行う度に「Decoising strenth」の値に「Denoising strength change factor」が乗算されます。
値を1以下にすると徐々に変化の度合いは小さくなり、値を1以上にすると徐々に変化の度合いが大きくなります。

画像を部分的に変化させる「Inpaint」の使い方
「img2img」には、画像全体ではなく特定の一部分だけを描き直す機能もあります。
「Inpaint a part of image」を選択して、先ほどと同じように元画像を読み込みます。
そして、元画像の変化させたい箇所をマウスでなぞってマスクをかけ、どのように変化させたいのか「Prompt」に文章を記入して「Generate」を押しましょう。
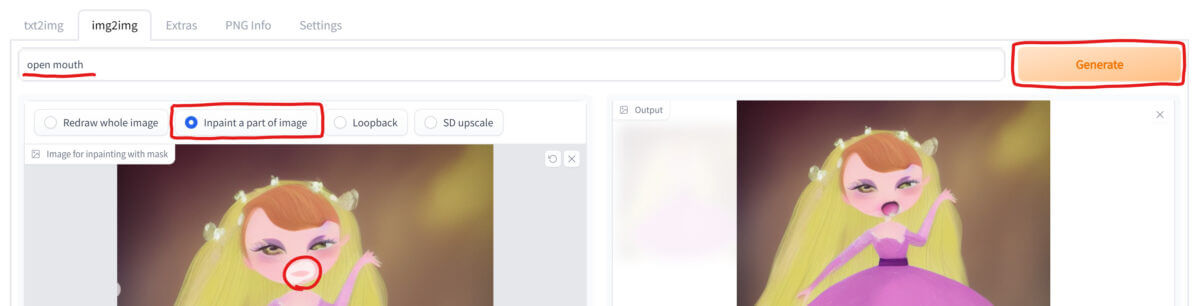
上の画像は、女性の口だけをプロンプト「open mouth」で開けさせた例です。
マスク周囲のぼやけを調整する
「Mask blur」の値を上げると、マスク周囲のぼやけが大きくなります。マスクの境界を自然に変化させたい時に使います。数字の単位はピクセル数です。

マスク領域の処理方法を選択する
画像の生成を行う前に、マスクされた領域内をどのように塗りつぶすかを選択します。

- fill:元画像に使われている色でマスク領域を塗りつぶす
- original:元画像をそのまま使う(塗りつぶさない)
- latent noise:latent space noiseで補間した画像でマスク領域を塗りつぶす
- latent nothing:latent space zeroesで補間した画像でマスク領域を塗りつぶす
より精細な画像を描画する
「Inpaint at full resolution」をONにすると、マスクされた領域を一旦ターゲット解像度までアップスケールしてから描画を行い、それをダウンスケールして元の画像に貼り付けます。

つまり、ターゲット解像度が512×512なら、マスク領域をそのサイズまで拡大したものにStable Diffusionをかけ、元のサイズに戻す。画像がより精細に描画される事になりますね。
マスク領域を反転させる
「Inpaint masked」を選択するとマスク領域内に画像を描画し、「Inpaint not masked」を選択するとマスク領域外に画像を描画します。

大きな「img2img」画像を生成する「SD upscale」の使い方
「img2img」タブの「SD upscale」を選択すると、通常ならVRAM不足で生成できないサイズの画像を生成できます。

仕組みとしては、元画像を細かく分割してそれぞれに「img2img」を適用した後、全ての画像をつなぎ合わせて1枚の画像に戻すという処理を行っています。
元画像に大きな画像を使用したり、結果となる画像を大きなサイズにしたりできます。
細分化した画像のつなぎ目をスムーズにする
「Tile overlap」の値を変更する事で、細分化した画像のつなぎ目をスムーズにする事ができます。
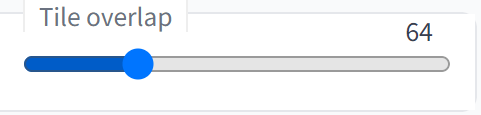
細かく分割した画像同士のつなぎ目はどうしても目立ってしまうので、画像の境目を重ね合わせるようにして目立たないようにします。その重なり具合を指定するのがこのパラメータです。値はピクセル単位で指定します。
拡大方法を指定する
「Upscaler」で画像の拡大方法を指定する事ができます。

- None:元画像と同じサイズの画像を生成します
- Lanczos:従来方式のLanczosを使って、元画像の4倍サイズの画像を生成します
- Real-ESRGAN 4x plus:AI超解像技術Real-ESRGAN 4x plusで元画像の4倍サイズの画像を生成します
- Real-ESRGAN 4x plus anime 6B:上記のアニメ向けモデルで元画像の4倍サイズの画像を生成します
- Real-ESRGAN 2x plus:AI超解像技術Real-ESRGAN 2x plusで元画像の4倍サイズの画像を生成します
AIを使ってキレイに画像を拡大する「Extras」の使い方
Stable Diffusionを使って生成した画像などを、「Real-ESRGAN」などのAIを駆使してキレイに拡大する事ができます。
上部のタブから「Extras」を選択し、Sourceに元となる画像を読み込みます。「Resize」で拡大率を指定したらページ下部の「Generate」を押して実行します。
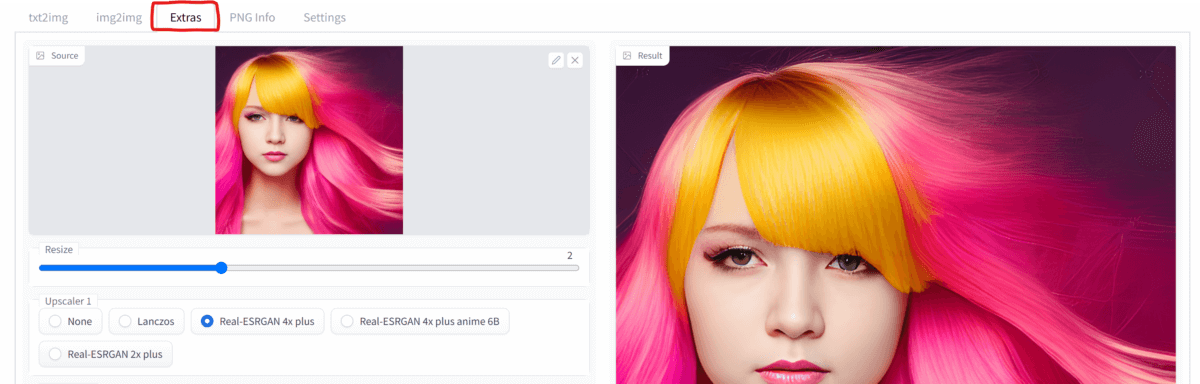
拡大方法を指定する
「Upscaler 1」で画像の拡大方法を指定します。
- None:拡大を行いません
- Lanczos:従来方式のLanczosを使っ画像を拡大します
- Real-ESRGAN 4x plus:AI超解像技術Real-ESRGAN 4x plusを使って画像を拡大します
- Real-ESRGAN 4x plus anime 6B:上記のアニメ向けモデルを使って画像を拡大します
- Real-ESRGAN 2x plus:AI超解像技術Real-ESRGAN 2x plusを使って画像を拡大します
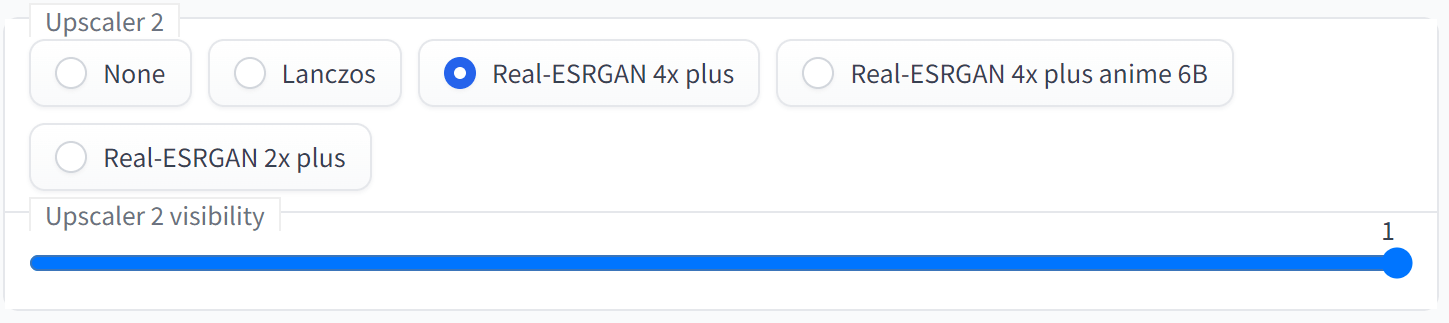
さらに「Upscaler 2」で、追加の拡大方法を指定できます。「Upscaler 2 visibility」で「Upscaler 2」の効果量を指定します。
人物や動物の顔を補正する
「GFPGAN visibility」に値を設定すると、「txt2img」の項目でご紹介した「Restore Faces」と同様にAIを使って顔の補正ができます。値が大きいほど最終結果に対しての「GFPGAN」の効果量が大きくなります。

「CodeFormer」も「GFPGAN」と同じく人物の顔を補正したり、劣化した写真を復元できるAIです。
「CodeFormer visibility」の値が大きいほど最終結果に対しての「CodeFormer」の効果量が大きくなります。また、「CodeFormer weight」の値が小さいほどAIによる補正が強くかかります。

画像の生成方法を再確認できる「PNG Info」の使い方
通常なら、画像生成に使った文章やシード値などの情報はあらかじめメモしておかないと同じ画像は二度と生成できなくなります。
しかし、このアプリで生成した画像にはそれらの情報がメタデータとして含まれているため、画像をドラッグ&ドロップするだけで再確認ができるのです!
上部の「PNG Info」タブを開き、画像を読み込んで「送信」ボタンを押すだけです。
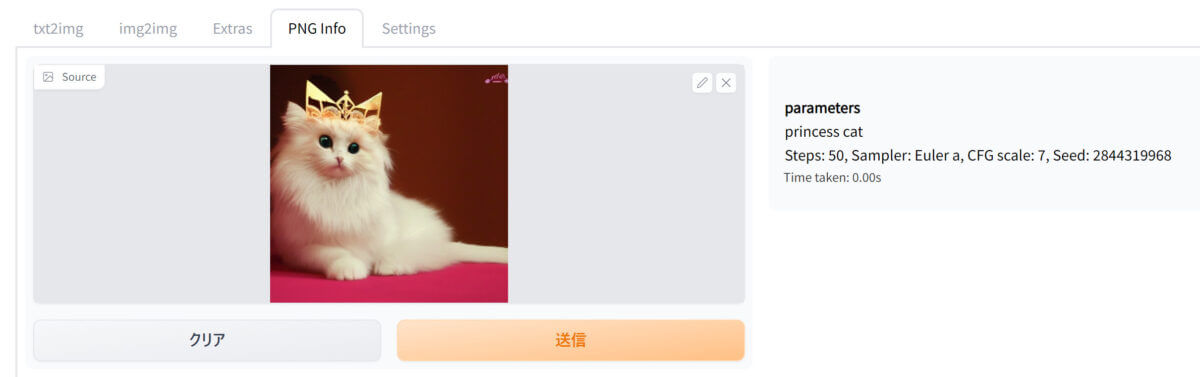
右側に画像を生成するための情報が表示されます。
独自に学習させた絵柄やキャラクターを生成できる「Textual Inversion」の使い方
日本で炎上した「mimic」というサービスのように、AIに追加で学習させた絵柄やキャラクターを画像に用いる事ができる機能が「Textual Inversion」です。
ここではAIに新たな画像を学習させる方法は解説しませんが、事前学習済みの「.pt」ファイルを使用する方法をご紹介します。
「webui.py」と同じ場所(ルートディレクトリ)に「embeddings」という名前のフォルダを作成し、そこに「.pt」ファイルを置きます。

このファイルの「ファイル名」をプロンプトに含める事で、学習した絵柄やキャラクターを使って画像を生成する事ができます。