
お絵かきAI「Stable Diffusion」は文章から画像を生成する事ができますが、特定のキャラクターを再現するのは困難です(というかほぼ不可能)
しかし、描かせたいキャラクターの画像を複数枚、追加学習させる事ができる「Dreambooth」という方法を使えば、特定のキャラクターに別のポーズを取らせたり、自分の絵柄に似たキャラクターを生み出す事が可能になります。
「mimic」というサービスで問題になったように、他人の作品を勝手に学習させて「なりすまし」を行うといった悪用は厳禁です!あくまで自分自身の創作活動の補助としてご活用くださいね。
クリエイター目線で考えると、Dreamboothを使って作成した自作キャラクターを下絵に利用する事で作品のクオリティアップや作業の効率化に活用できるのではないかと考えています。
ただ、Dreamboothには大量のメモリ(VRAM)が必要で、現時点ではまだローカルで動作させるのは困難です。
この記事では無料で使えるオンライン機械学習サービス「Google Colaboratory」を使ってDreamboothを行い、作成したモデルをローカルで使用する方法をご紹介します。
事前にHuggingFaceのアクセストークンを取得しておく
Dreamboothを行う前にHuggingFaceのアクセストークンを作成しておく必要があります。
この記事をご覧の方はすでに取得済みの方も多いと思いますが、まだの方は以下の記事を参考にしてアクセストークンを作成しておいてください。

Google Colaboratoryを起動する
ShivamShriraoさんが作成したGoogle Colaboratoryを利用させていただきます。以下のリンクにアクセスしてみてください。
「Google Colaboratory」とは、Googleが提供している機械学習・深層学習サービスです。無料で利用できますが、起動から12時間が経過すると強制的にリセットされます。(起動してから全く操作せず切断状態になり90分が経過した場合もリセットされます)
ページが開いたら、まずはメニューバーから「ファイル」→「ドライブにコピーを保存」を選択して、自身のGoogleドライブのアカウントにコピーを作成しましょう。元のページを編集してしまわないように注意。
コピーを作成すると自動的に「DreamBooth_Stable_Diffusion.ipynb のコピー」という名前のページが開くと思いますが、開かなかった場合は自身のGoogleドライブの「Colab Notebooks」フォルダに保存されていますのでそこから開いてください。
基本的には、上の項目から順番に実行していけばOKです。
GPUを使用する設定になっているか確認
まずはメニューバーから「ランタイム」「ランタイムのタイプを変更」をクリックします。
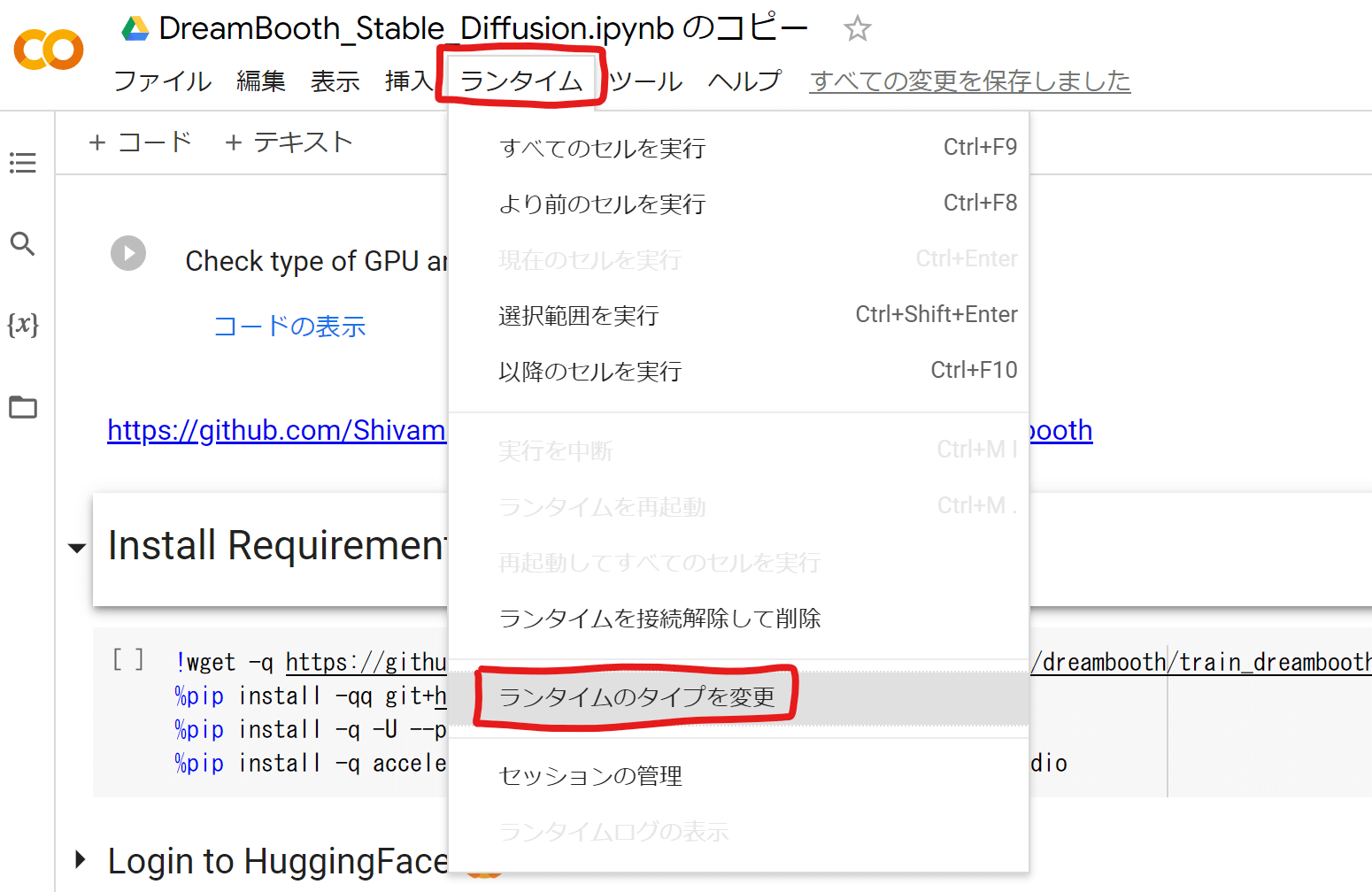
ハードウェアアクセラレータの設定が「GPU」になっている事を確認して下さい。もし違う場合は「GPU」に変更して「保存」します。
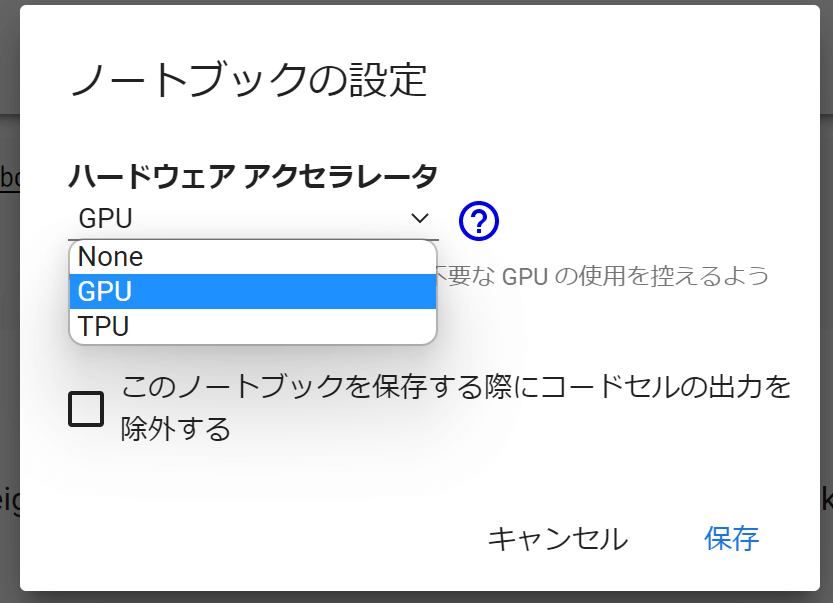
使用できるGPUの種類を確認
続いて使用できるGPUの種類を確認します。「Check type of GPU and VRAM available.」の実行ボタンをクリックしてみてください。

結果が下に出力されます。無料版では基本的に「Tesla T4」が割り当てられますが、もし12.5GB以下のVRAMのものが割り当てられている場合は実行できないので、リロードして「Tesla T4」を引き当ててください。
必要なライブラリをインストール
「Install Requirements」の実行ボタンをクリックして必要なライブラリをインストールします。
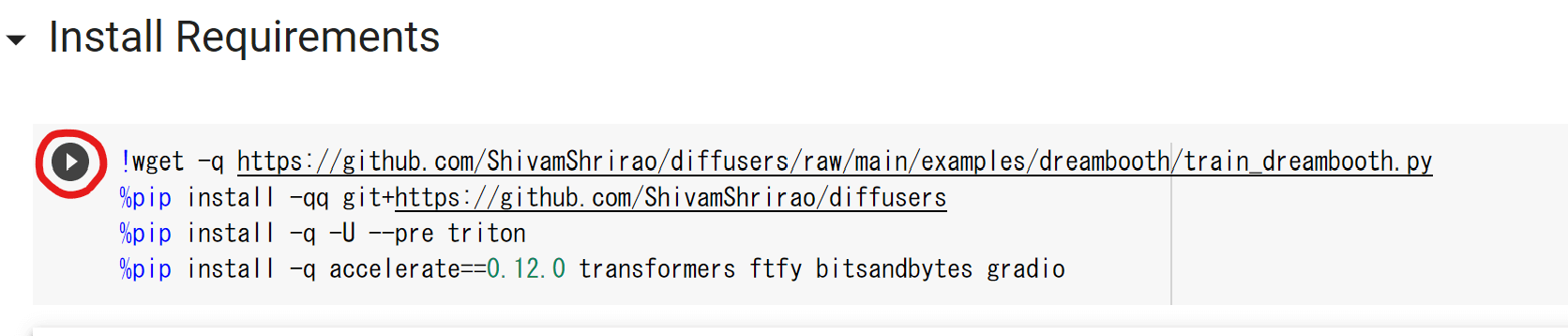
少し時間がかかるので、処理が完了するまでお待ち下さい。
HuggingFaceのアクセストークンを入力
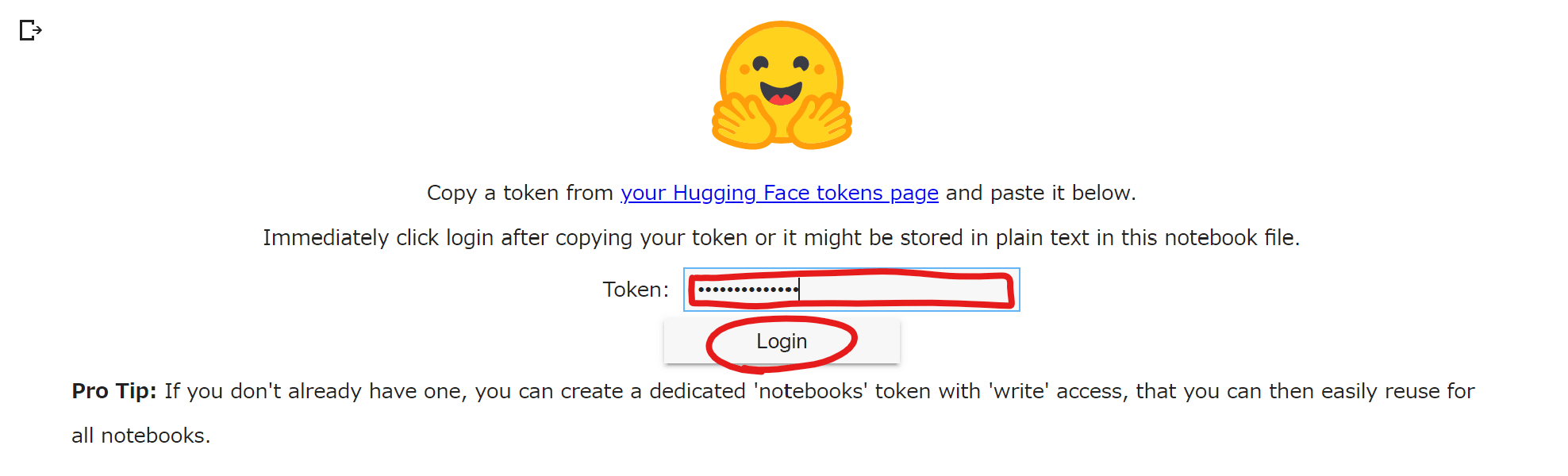
「Login to HuggingFace」の実行ボタンをクリックします。

するとHuggingFaceのアクセストークン入力欄が表示されるので、ご自身のアクセストークンを入力してから「Login」をクリック。
xformersのインストール
「Install xformers from precompiled wheel」の実行ボタンをクリックします。

Dreamboothの設定をする
次の「Settings and run」では、実行ボタンをクリックする前に、いくつかの設定を入力します。
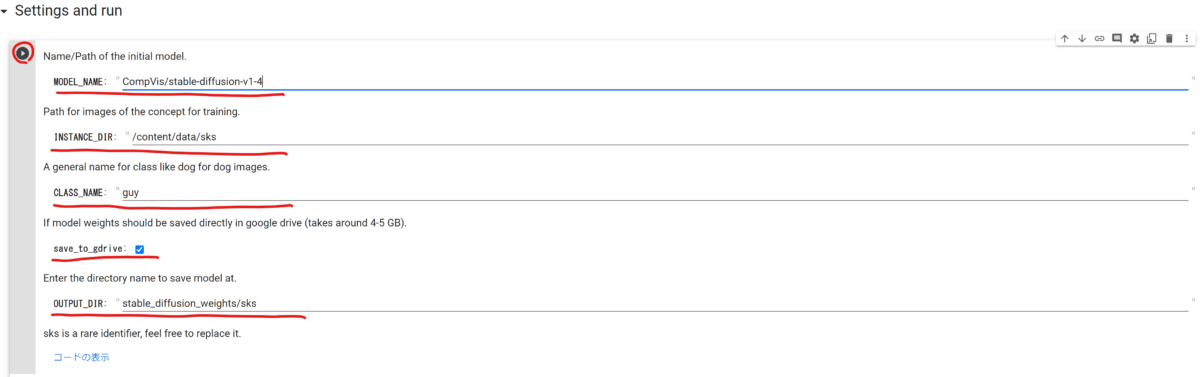
MODEL_NAME
Dreamboothを行う元になるモデルのパスを指定します。主なものは
- 「CompVis/stable-diffusion-v1-4」:基本的なStableDiffusionモデル
- 「hakurei/waifu-diffusion」:二次元絵に特化したモデル「Waifu-Diffusion 1.2」
- 「Nilaier/Waifu-Diffusers」:二次元絵に特化したモデル「Waifu-Diffusion 1.3」
- 「naclbit/trinart_stable_diffusion_v2,diffusers-115k」:二次元絵に特化したモデル
が利用できます。
後述する「OUTPUT_DIR」に保存されたDreambooth適用後モデルのパスを入力すれば、Dreambooth適用後モデルをさらにDreamboothで追加学習する事もできます。
例)「/content/drive/MyDrive/stable_diffusion_weights/sks」と入力
INSTANCE_DIR
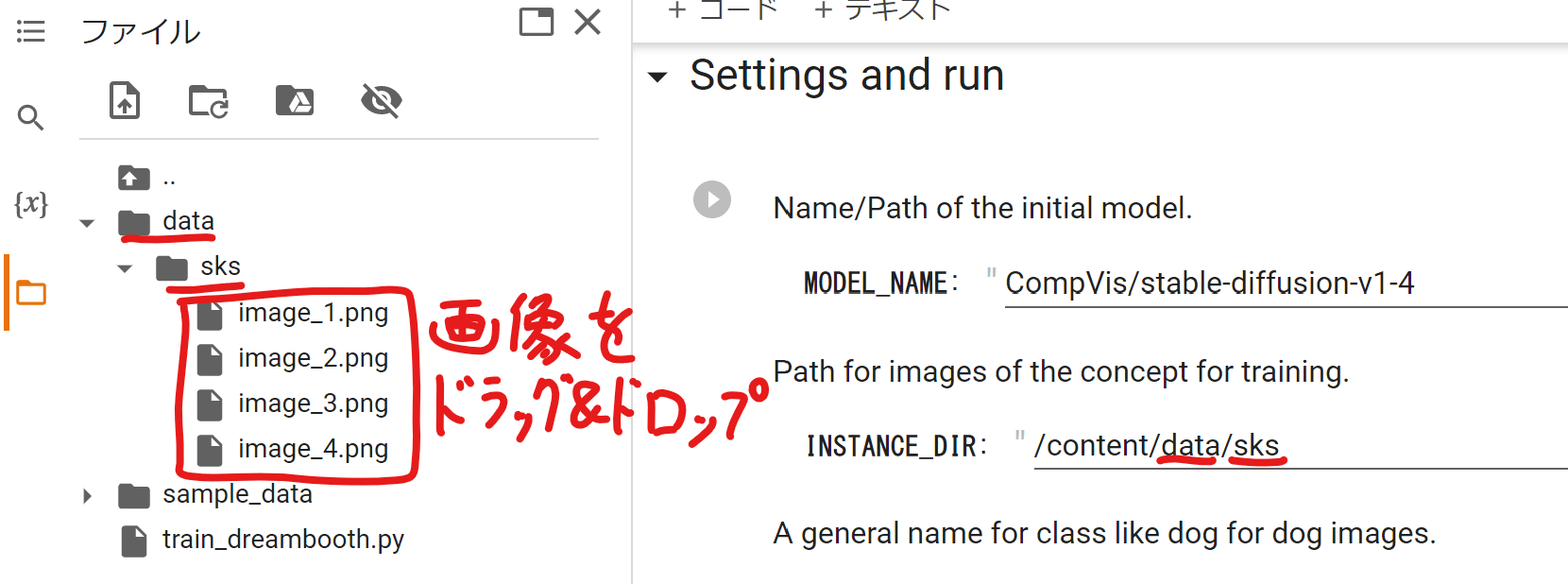
Dreamboothを実行する際に覚えさせたい画像ファイルを置くパスを指定します。
画面左のフォルダアイコンをクリックするとファイル一覧(/contentディレクトリ)が表示されますので、そこで右クリックして上記パスに指定したフォルダを作成しましょう。
フォルダを作成したら、そこに複数の画像ファイルをドラッグ&ドロップしてアップロードします。画像ファイルは「512×512」サイズにトリミングしておきましょう。
CLASS_NAME
覚えさせたい画像の一般名称です。
例えば犬の画像を覚えさせるなら「dog」、女性キャラの画像を覚えさせるなら「girl」のように入力します。
save_to_gdrive
完成したモデルをGoogleドライブに保存するかどうか。基本的にここはチェックを入れておけばOKです。
4~5GBの容量が必要なので空き容量は確保しておきましょう。
OUTPUT_DIR
完成したモデルをGoogleドライブに保存する場合の保存先です。
ここまでの項目を全て入力し終えたら、実行ボタンをクリックしましょう。
Googleドライブへのアクセス許可を求められたら、「Googleドライブに接続」をクリックしてアカウントを選択し、「許可」をクリックしてください。

上記の手順で設定していれば「Upload your images by running this cell.」と書かれた項目は実行不要です。元になる画像をアップロードするための箇所ですが、上記のようにファイルを直接アップロードした方が速くて使い勝手が良いです。
学習を開始する
以下の箇所の「instance prompt」にプロンプトで使用したい固有の文字列を入力し、「class prompt」にプロンプトで使用する学習対象の一般名称を入力します。
ひとまずは、変更せずに以下のままにしておきましょう。実際にプロンプトで学習対象を呼び出す時は「sks girl」のようにsks+一般名称で使用できます。
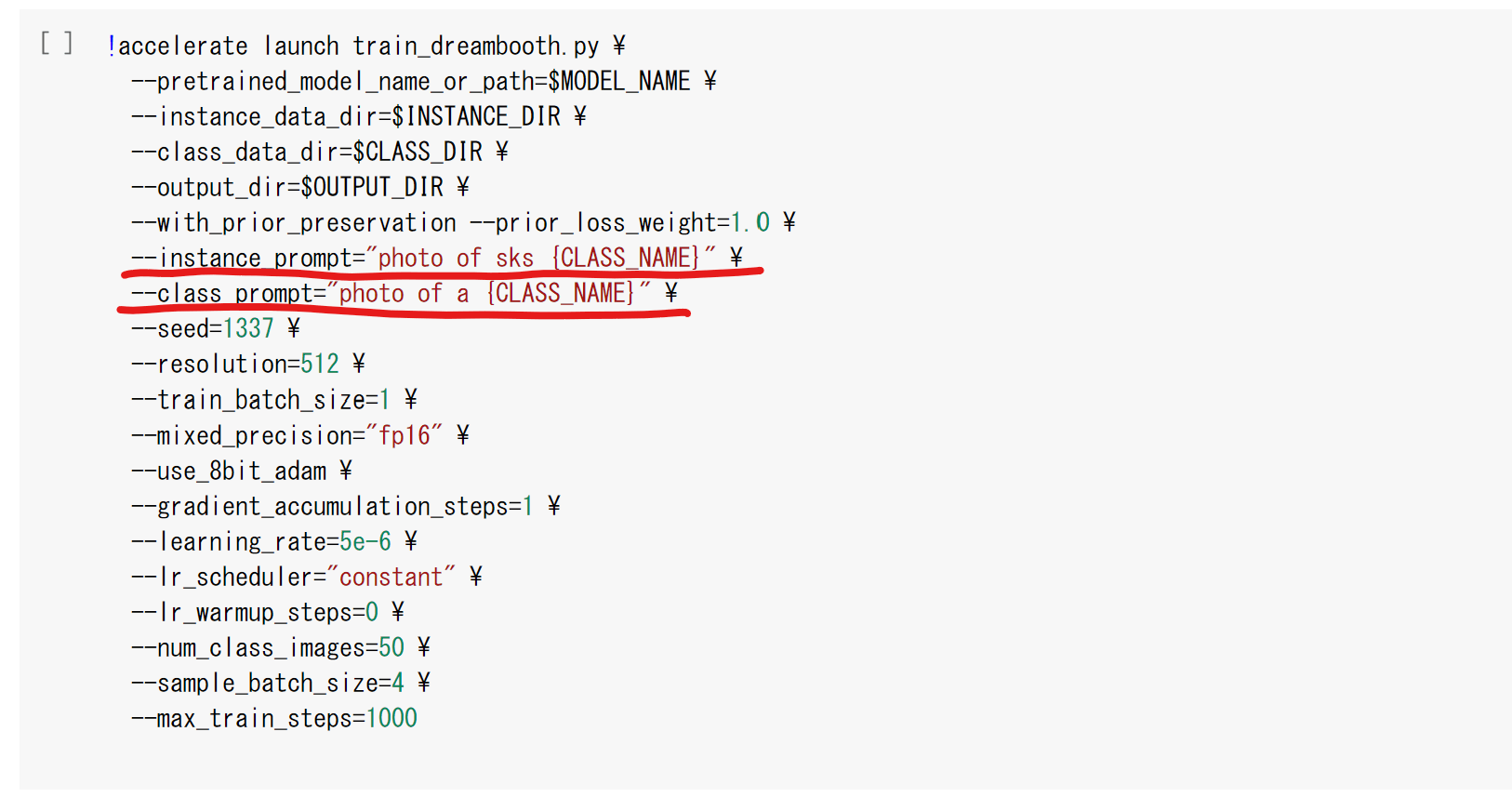
なお、「max_train_steps」で学習のステップ数を変更できます。学習する画像の枚数×200あたりを目安に試してみると良いと思います。
入力が完了したら、実行ボタンをクリックして学習を開始します。
学習にはかなり時間がかかりますので気長に待ちましょう。
ckpt形式に変換する
学習後に、「Convert weights to ckpt to use in web UIs like AUTOMATIC1111.」の2つの実行ボタンを上から順番にクリックすれば完成したモデルデータを「ckpt」形式に変換して保存できます。
「ckpt」形式のモデルデータはAUTOMATIC1111さんが開発している「Stable Diffusion web UI」を使ってローカルで使用できるのでとても便利ですよ!

Dreamboothで作成したモデルを「Stable Diffusion web UI」に組み込む方法は下記を参考
