
前回の記事でご紹介した「Stable Diffusion」をローカル環境で実行する方法は、8GBメモリのGPUでは「512×512」サイズの画像までしか生成できませんでした。

また、「txt2img(文章から画像を生成)」はできましたが、「img2img(画像から画像を生成)」ができませんでした。
今回ご紹介する方法は、画像生成の速度を犠牲にする代わりにそれらを可能にするものです。
高速&大量に文章から画像を生成する場合は、前回ご紹介した方法が適しています。また、今回ご紹介する方法を導入する過程で、前回の方法が使えなくなる可能性があります(コマンドプロンプトから実行できなくなる)のでご了承ください。
記事の後半では、今回新たに導入する「Anaconda」環境で、前回と同じ「diffusers」を使用する方法についても触れます。
まずは必要な環境を整える
まずは以下の環境を整えておく必要があります。
- 「Hugging Face」ライセンスに同意
- 「Python」をインストール
- GPUのドライバを更新しておく
- 「CUDA Toolkit」をインストールする
- cuDNNをインストールする
これらの手順は前回の記事で解説しましたので、そちらをご覧下さい。
上記の準備ができたら、さらに以下のソフトをインストールしていきます。
Gitをインストールする
Git公式サイト(https://gitforwindows.org/)からインストーラをダウンロードしてインストールします

基本的にはデフォルト設定のままどんどん次へ進んでいってOKです。
エディタを選択する場面ではご自身が使用しているエディタを選んでください。筆者はゲーム制作をするために「Visual Studio Code」を使用していたので、それを選んでおきました。特に指定が無い場合はデフォルトのままでも大丈夫そうです。
まだまだ設定項目が続きますが、特に問題無ければデフォルトのままで最後まで進んでインストールを完了してください。
Anacondaをインストールする
Anaconda(https://www.anaconda.com/products/distribution)をダウンロードしてインストールします。

インストールは基本的にどんどん次へ進んでいけばOKですが、最後にパスを通すかどうか聞かれるところだけはチェックマークを入れておきましょう。
インストールが完了すると「Anaconda Prompt」を使用できるようになります。アプリが見つからない場合はWindowsの検索機能を使えば見つかると思いますので、デスクトップ等にショートカットを作成しておくと便利です。
PyTorchをインストールする
「Anaconda Prompt」を起動し、以下のコマンドを入力していきます。1行毎にEnterキーを押して進んでください。
conda init
conda create -n PyTorch「Proceed ([y]/n)?」と聞かれるので、 y を入力してEnterキーを押します。続いて、
conda activate PyTorchそれでは、PyTorchをインストールします。PyTorch公式サイト(https://pytorch.org/)を見ると環境に合わせたインストールコマンドを知る事ができます。
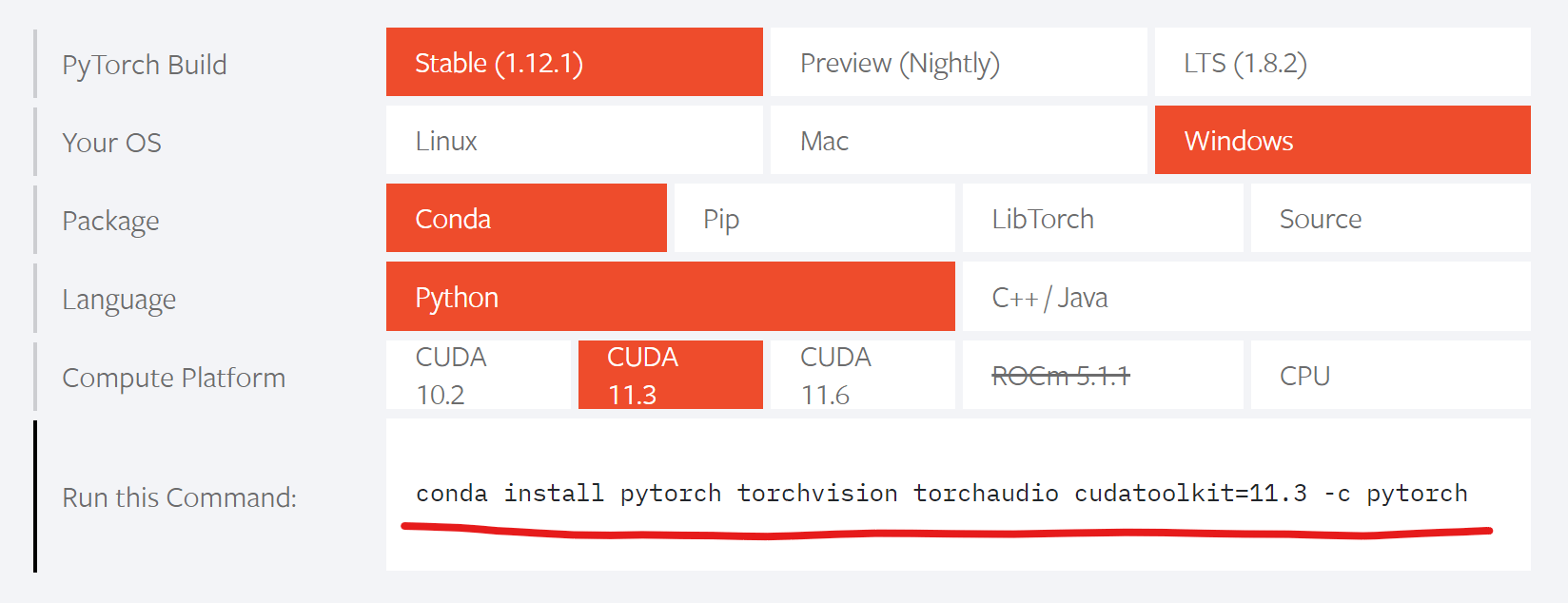
公式サイトの指示通り、以下のコマンドを入力しましょう。
conda install pytorch torchvision torchaudio cudatoolkit=11.3 -c pytorch「Proceed ([y]/n)?」と聞かれるので y を入力してEnterキー。インストールが完了したら、
python
import torch
torch.cuda.is_available()でGPUが使えるかどうか確認。「True」が表示されたらOKです。
一度プロンプトを閉じた後に再度上記の確認を行う場合は、事前に「conda activate PyTorch」が必要です
以下のコマンドでPythonを終了しておきます。
exit()Stable Diffusionをインストールする
続いて、「Stable Diffusion」をインストールしていきます。メモリの少ないGPUでは簡単にエラーが起きてしまうので、速度が遅い代わりに少ないメモリでも動作するフォーク版をインストールします。
以下のコマンドを入力して実行しましょう。
git clone https://github.com/basujindal/stable-diffusionデフォルトではご自身のユーザーフォルダ「C:\Users\ユーザー名」の中に「stable-diffusion」フォルダがインストールされていると思います。
以下のコマンドを1行ずつEnterキーで実行して環境を設定していきます。処理が完了するまでしばらく待ちましょう。
cd stable-diffusion
conda env create -f environment.yaml
conda activate ldm続いて、「Hugging Face」からモデルをダウンロードします。
git clone https://huggingface.co/CompVis/stable-diffusion-v-1-4-original以下のウィンドウが表示された場合は、「Hugging Face」のユーザー名(メールアドレス)とパスワードを入力してから「OK」をクリック。
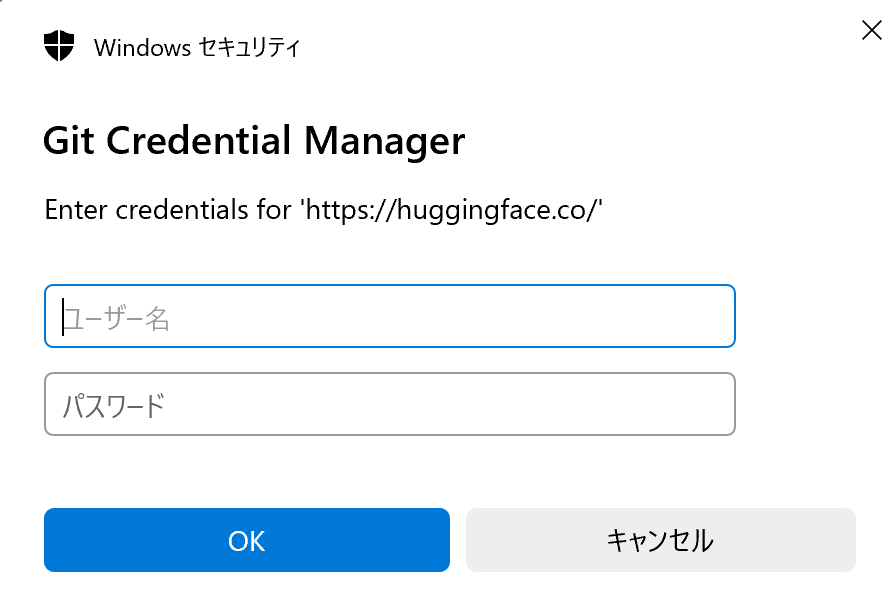
モデルのクローンにはかなり時間がかかるので、気長にお待ち下さい。
続いて、エクスプローラーから「C:\Users\ユーザー名\stable-diffusion」フォルダを開きます。
すると先ほどクローンした「stable-diffusion-v-1-4-original」フォルダがありますので「stable-diffusion-v1」にリネーム(名前を変更)します。

上記でリネームした「stable-diffusion-v1」フォルダを開くと、「sd-v1-4.ckpt」ファイルがあるので、こちらは「model.ckpt」にリネームします。
さらに、「stable-diffusion-v1」フォルダを、「C:\Users\ユーザー名\stable-diffusion\models\ldm」の中に移動させます。
これでローカルで「Stable Diffusion」を使用する準備が完了しました。
txt2img(文章から画像を生成)を試してみる
では、実際に画像を生成してみましょう。
なお、「Anaconda Prompt」を再起動した後などは、もう一度「Stable Diffusion」を使用する準備が必要です。
cd stable-diffusion
conda activate ldm準備ができたら、試しに以下のコマンドを実行して画像を生成してみましょう!
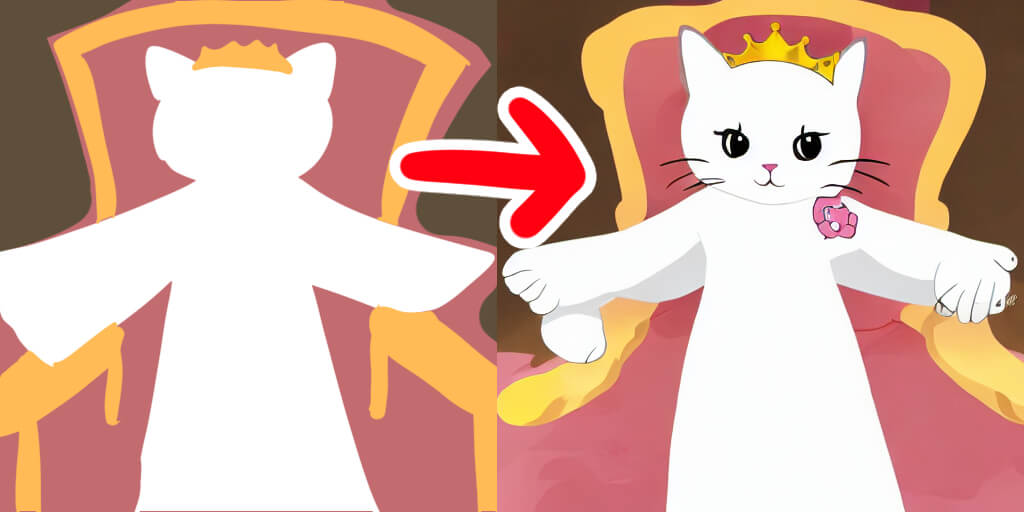
python optimizedSD/optimized_txt2img.py --prompt "princess cat" --W 512 --H 512 --seed 27 --n_iter 1 --n_samples 1 --ddim_steps 50以下のような「プリンセスキャット」の画像が生成されました!

コマンドの内容を簡単に説明します
・「--prompt」:画像の元になる文章(プロンプト)です
・「--W」:画像サイズの幅(64の倍数)です。大きすぎるとメモリが足りなくなります。
・「--H」:画像サイズの高さ(64の倍数)です。大きすぎるとメモリが足りなくなります。
・「--seed」:乱数のシード値を設定できます。同じ値で実行すれば同じ結果が得られます。
・「--n_iter」:画像生成をこの回数だけ繰り返します。使用メモリには影響しません。
・「--n_samples」:1回あたりの生成数を指定します。値が大きいほどメモリを使用します。
・「--ddim_steps」:生成される画像の品質を調整するための値ですエラーが出たときの対処法
画像生成中に「No module named ‘taming’」というエラーが出た時は、
conda remove -n ldm --allで一度環境を削除してから、再びStable Diffusionの環境設定作業を行ってみてください。
img2img(画像から画像を生成)を試してみる
「Anaconda Prompt」を再起動した後などは、もう一度「Stable Diffusion」を使用する準備が必要です。
cd stable-diffusion
conda activate ldm準備ができたら、試しに以下のコマンドを実行して画像を生成してみましょう!「元画像のファイルパス」の部分は使用したい画像のファイルパスに書き換えてください。
python optimizedSD/optimized_img2img.py --prompt "princess cat" --init-img 元画像のファイルパス --strength 0.8 --n_iter 1 --n_samples 1元画像として使用したいファイルの上で右クリック→「パスのコピー」をすると簡単にファイルパスを取得できます
以下のような「プリンセスキャット」の画像が生成されました!
パラメータは「text2img」とほぼ同じですが、以下のパラメータが追加されています。
・「--strength」:0.0~1.0の間で指定。値が大きいほど変化が大きくなるちなみにstrengthを0.9で実行した場合はこうなりました。変わりすぎやろ。

Anaconda環境で「diffusers」を使用する方法
ここからは、今回新たに導入したAnaconda環境で前回の記事と同じ「diffusers」を使ってStable Diffusionを動かす方法も解説しておきます。
高速に、大量に画像を生成したい人はこちらも併せて導入しておくと便利です。
diffusers環境の作成
まずは新しい環境を作成しましょう。「Anaconda Prompt」を起動し、以下のコマンドを入力します。
conda create -n diffusers「Proceed ([y]/n)?」と聞かれるので、 y を入力してEnterキーを押します。続いて、
conda activate diffusersでdiffusers環境を有効にします。
PyTorchをインストールする
diffusers環境にもPyTorchをインストールします。
conda install pytorch torchvision torchaudio cudatoolkit=11.3 -c pytorch「Proceed ([y]/n)?」と聞かれるので y を入力してEnterキー。インストールが完了したら、
python
import torch
torch.cuda.is_available()でGPUが使えるかどうか確認。「True」が表示されたらOKです。
以下のコマンドでPythonを終了しておきます。
exit()diffusersをインストールする
pip install diffusers==0.2.4 transformers scipy ftfyでdiffusersをインストールします。
txt2img(文章から画像を生成)を実行する
では、実際に画像を生成してみましょう。
なお、「Anaconda Prompt」を再起動した後などは、もう一度diffusers環境の有効化が必要です。
conda activate diffusersここから先は、前回の記事と同様のやり方で画像を生成することが可能です。
前回の記事の「Stable Diffusion」で画像を生成するの項目を参照してください。