
以前、お絵かきAI「Midjourney」について徹底解説しました。

「Midjourney」は生成回数に制限があるので、試行錯誤しているとすぐに回数が無くなってしまいますし、生成速度も遅いのが難点でした。
しかしその後、「Stable Diffusion」という「Midjourney」以上に高品質と噂されるAIが公開されました。
こちらは無料かつ、ローカル環境で実行できるので生成速度が爆速です!

試行錯誤は「Stable Diffusion」で行って
プロンプトが定まったら「Midjourney」という手はアリかも
ただし、ローカルの環境構築は手強いです。GPUのスペックもかなり影響します。
とにかく筆者も自身のPC(GPUはGeForce RTX 3070Ti)に「Stable Diffusion」実行環境を構築してみましたので、その手順を公開します!
この記事でご紹介する方法は、「文章から画像を生成」したい人だけに向けた内容です。文章だけでなく、「画像から画像を生成」もしたい人は次の記事を優先してご覧下さい。

「Hugging Face」の準備
「Hugging Face」のページ(https://huggingface.co/CompVis/stable-diffusion-v1-4)にアクセスします。
まだ「Hugging Face」のアカウントを持っていない場合は、次の項目を参考にして新しいアカウントを作成しましょう。
すでに作成済みの方は、ログインするだけでOKです。
「Hugging Face」アカウントの作成
「Hugging Face」ページ上部の「Sign Up」をクリックして新しいアカウントを作成しましょう。

「Sign Up」ボタンをクリックすると、メールアドレスとパスワードの設定画面が表示されるので入力します。
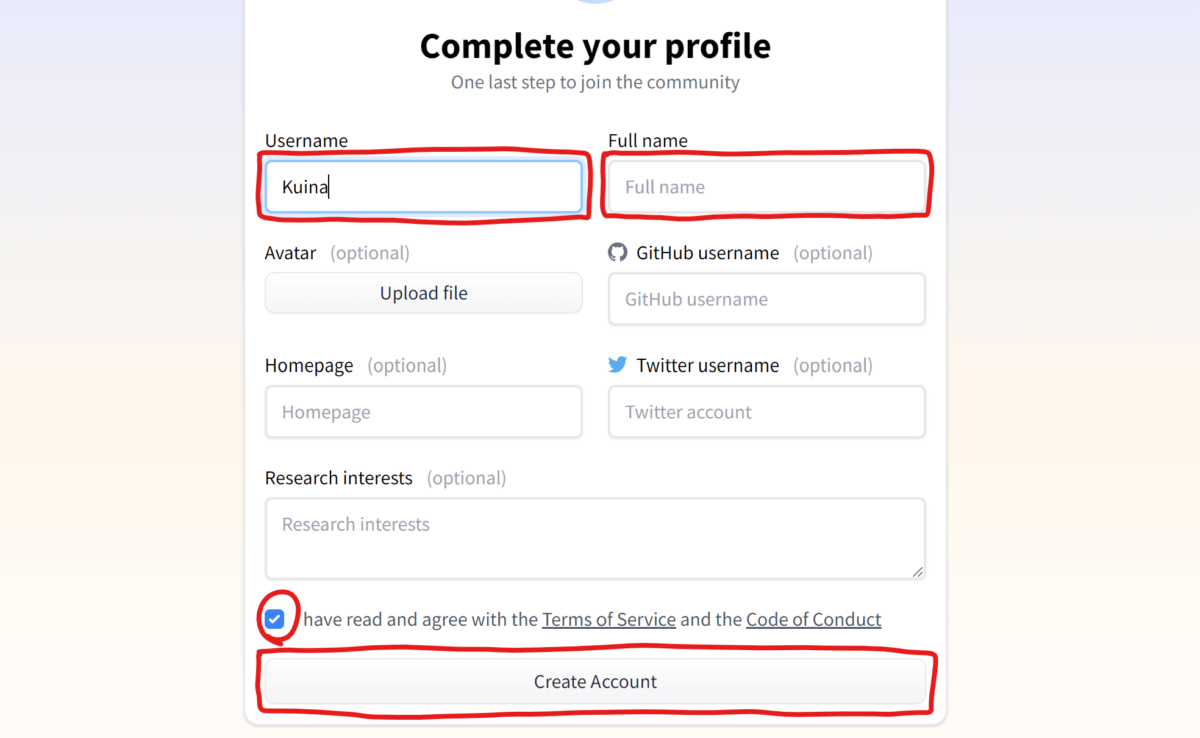
次にプロフィール作成画面が表示されるので、「ユーザー名」と「フルネーム(氏名)」を入力し、下部のチェック欄をクリックしてから「Create Account」ボタンを押してアカウント作成は完了です。
アカウント作成が完了したら先ほどのページ(https://huggingface.co/CompVis/stable-diffusion-v1-4)に戻り、次の手順に進みます。
ライセンスに同意する
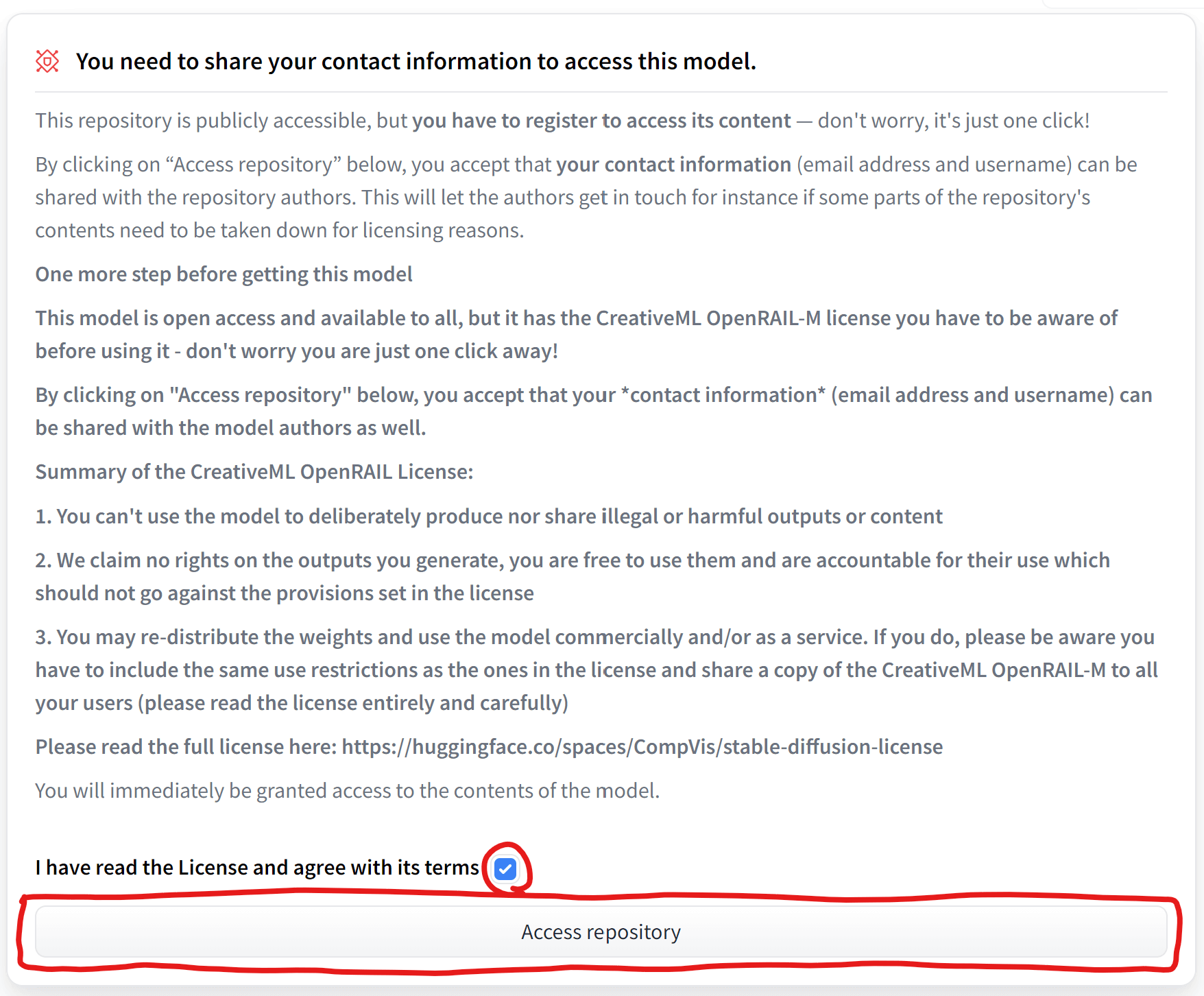
Stable Diffusionを利用するには「CreativeML OpenRAIL License」というライセンスに同意する必要がありますので、ご自身でよく確認してください。ライセンス全文:https://huggingface.co/spaces/CompVis/stable-diffusion-license
以下、ライセンスの簡単な説明になります。
- あなたは、違法または有害な出力やコンテンツを意図的に作成したり共有するためにモデルを使用することはできません。
- 私たちは、あなたが生成した出力に関する権利を主張しません。あなたはそれらを自由に使用することができ、ライセンスで設定された規定に反してはならないその使用について説明責任を負います。
- あなたは、重みを再配布し、モデルを商業的および/またはサービスとして使用することができます。その場合、ライセンスに記載されているものと同じ使用制限を含め、CreativeML OpenRAIL-Mのコピーをすべてのユーザーと共有しなければならないことに注意してください(ライセンスを完全にかつ注意深く読んでください)。
生成した画像は自由に商用利用もできるけど、
違法な画像を作った結果は自己責任だよ!
実在する人物や有名キャラクターに似せるのは危ないね
ライセンスを確認したら、ページ下部のチェック欄をクリックしてから、「Access repository」ボタンをクリックします。
アクセストークンを作成する
アクセストークンとは、「Gugging Face」のサービスに対してアプリケーションを認証するためのもので、あらかじめ作成しておく必要があります。
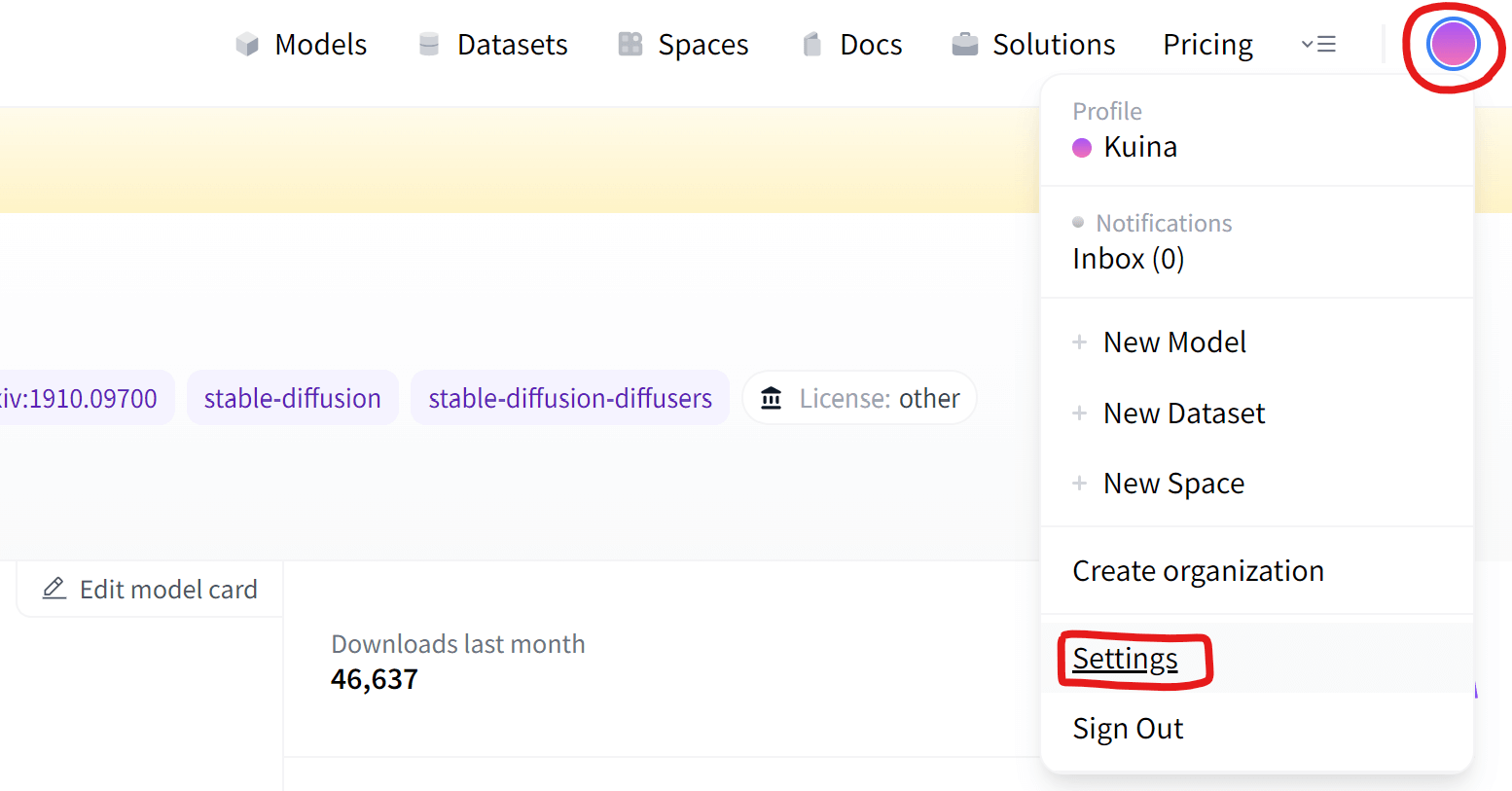
ページ右上のアカウントボタンをクリックして「Settings」を開きましょう。
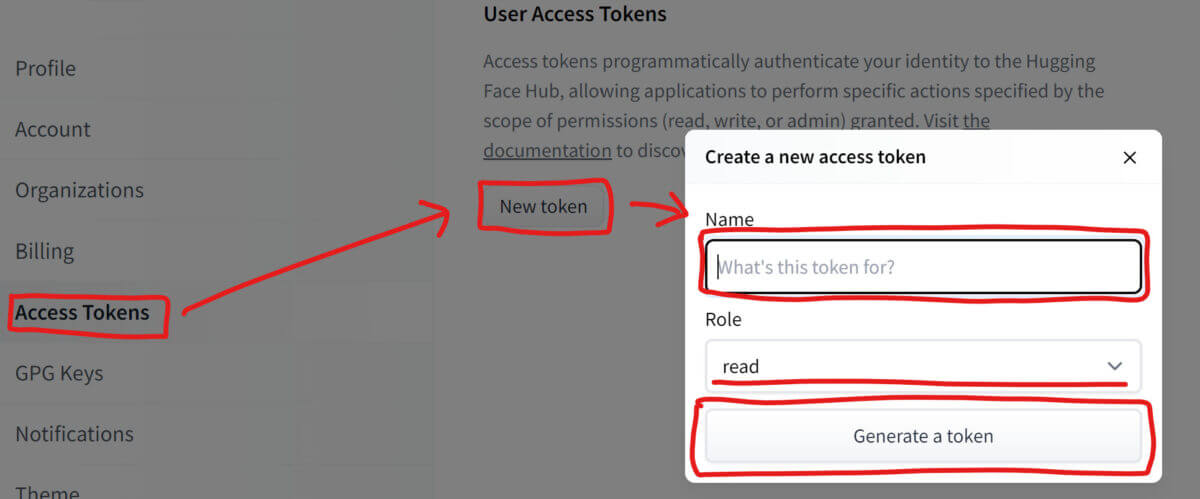
アカウント設定画面を開いたら、左側の「Access Tokens」をクリック、「New token」ボタンを押して、アクセストークンに適当な名前を付けましょう。「Generate a token」ボタンを押してトークンの作成は完了です。
「Python」をインストール
Pythonの公式ページ(https://www.python.org/)にアクセスし、「Downloads」から最新のPythonをダウンロードします。
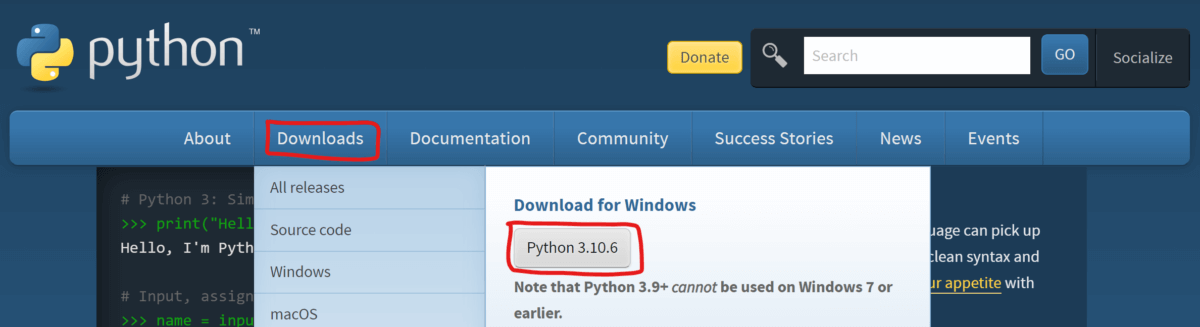
ダウンロードしたファイルを実行すると以下のウィンドウが表示されますので、「Add Python ○○ to PATH」にチェックを入れてから「Install Now」をクリックします。
インストールが完了したら「Close」をクリックして終了します。
GPUのドライバを更新しておく
NVIDIAのドライバが最新バージョンでない場合、公式サイト(https://www.nvidia.co.jp/Download/index.aspx?lang=jp)からダウンロードしてアップデートしておきます。

「CUDA Toolkit」をインストールする
次に、「CUDA Toolkit」(https://developer.nvidia.com/cuda-downloads)の最新バージョンをダウンロードしてインストールします。

cuDNNをインストールする
cuDNNをダウンロード(https://developer.nvidia.com/rdp/cudnn-download)するには、「NVIDIA」のアカウントでログインし、「NVIDIA Developer Program」のメンバーシップに登録しなければなりません。

もし、まだ「NVIDIA」のアカウントを持っていない場合は先に作成してから、メンバーシップに登録してください。
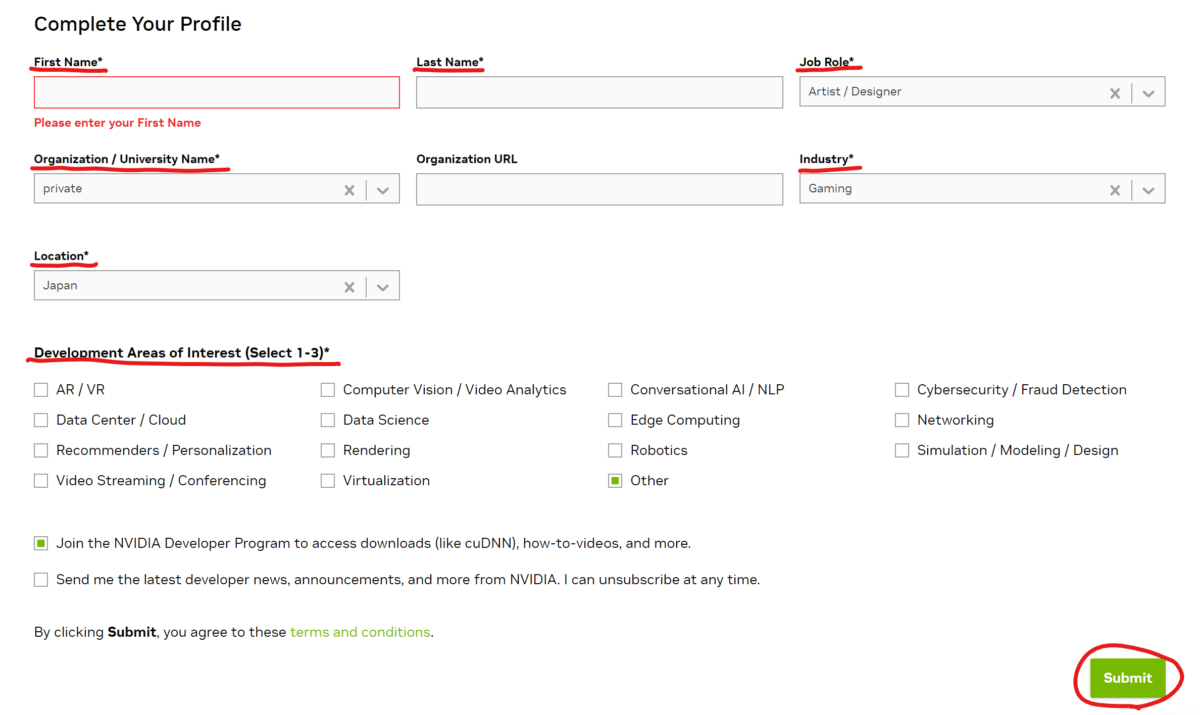
「NVIDIA Developer Program」に登録するには、氏名、職種、所属などの必須項目を入力する必要があります。入力が完了したら、「Submit」をクリックして登録完了です。
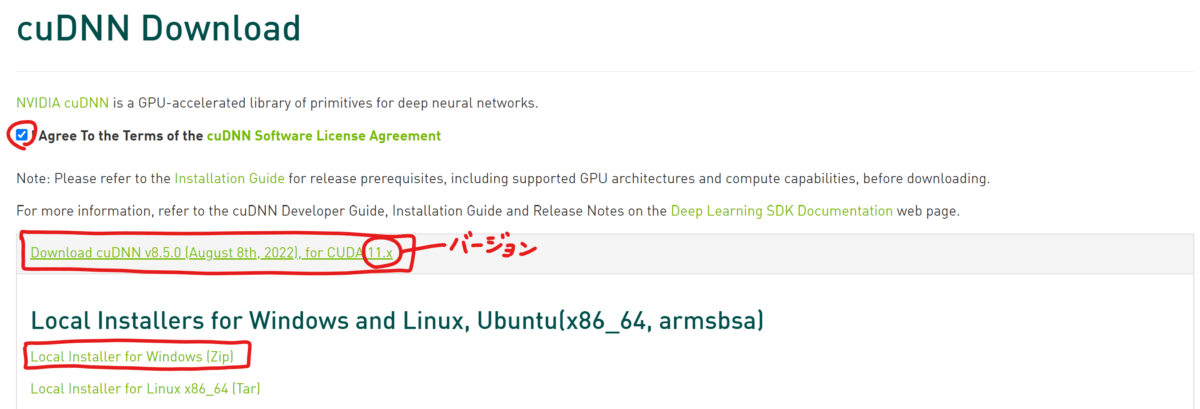
メンバーシップの登録が完了したら、cuDNNをダウンロード(https://developer.nvidia.com/rdp/cudnn-download)しましょう。バージョンは、先ほどインストールした「CUDA Toolkit」のバージョンに合わせます。
zipファイルのダウンロードが完了したら、解凍して、任意の場所に移動しておきます。自分は「C:\cuDNN」フォルダに入れました。
続いて、cuDNNにパスを通しましょう。
Windowsのスタートボタンの上で右クリックして「システム」を開き、「システムの詳細設定」をクリックします。
「環境変数」を開き、システム環境変数の一覧から「Path」を選択して「編集」をクリック。
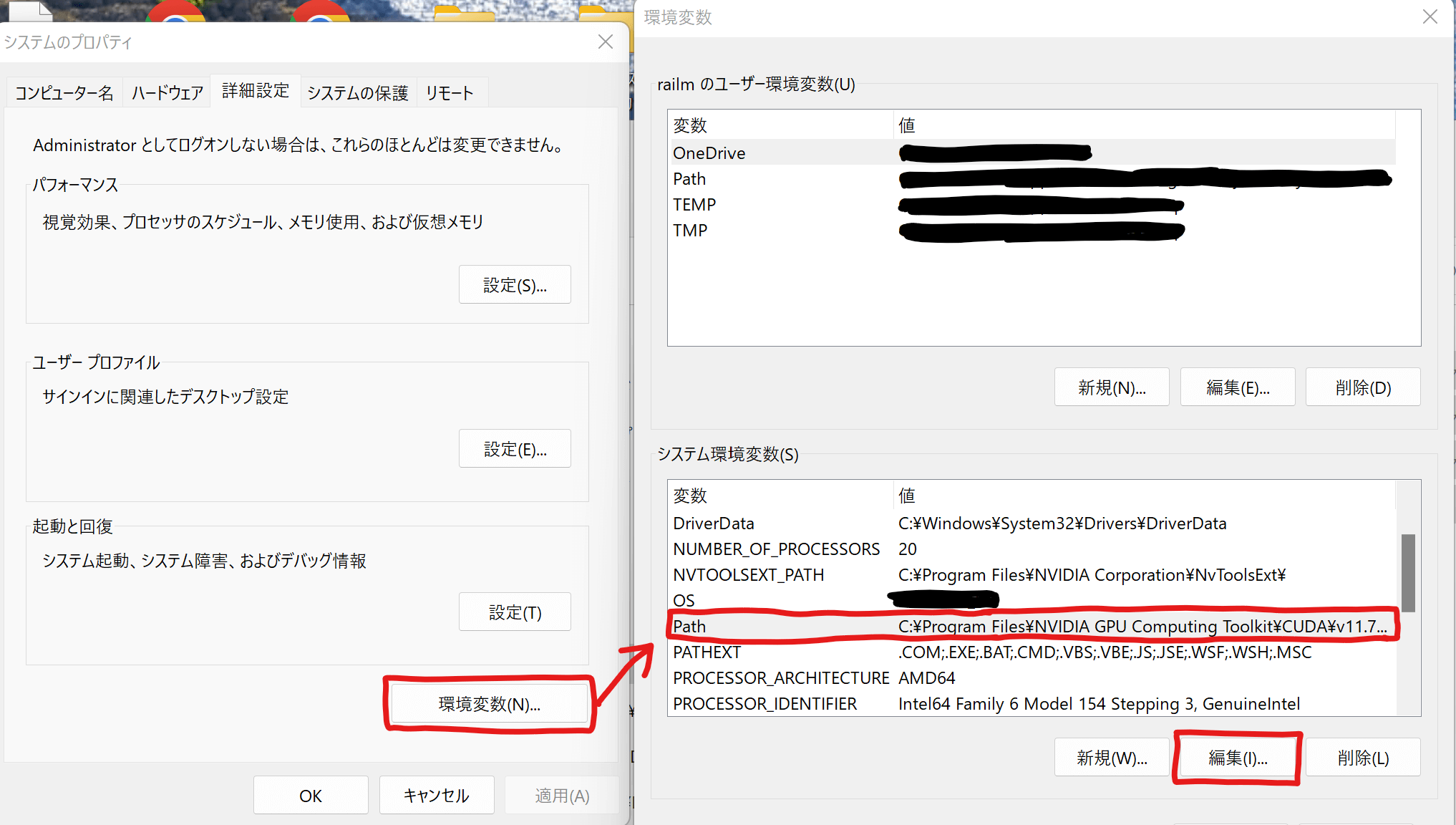
次に「新規」をクリックして、先ほどダウンロードしたフォルダ内にある「bin」フォルダへのパスを入力します。(例:「C:\cuDNN\bin」)
完了したら「OK」をクリックして終了です。
PyTorchをインストールする
続いて「PyTorch」をインストールします。公式サイト(https://pytorch.org/)にアクセスし、少し下にスクロールしたところにある以下の箇所で、自身の環境をクリックして選択します。
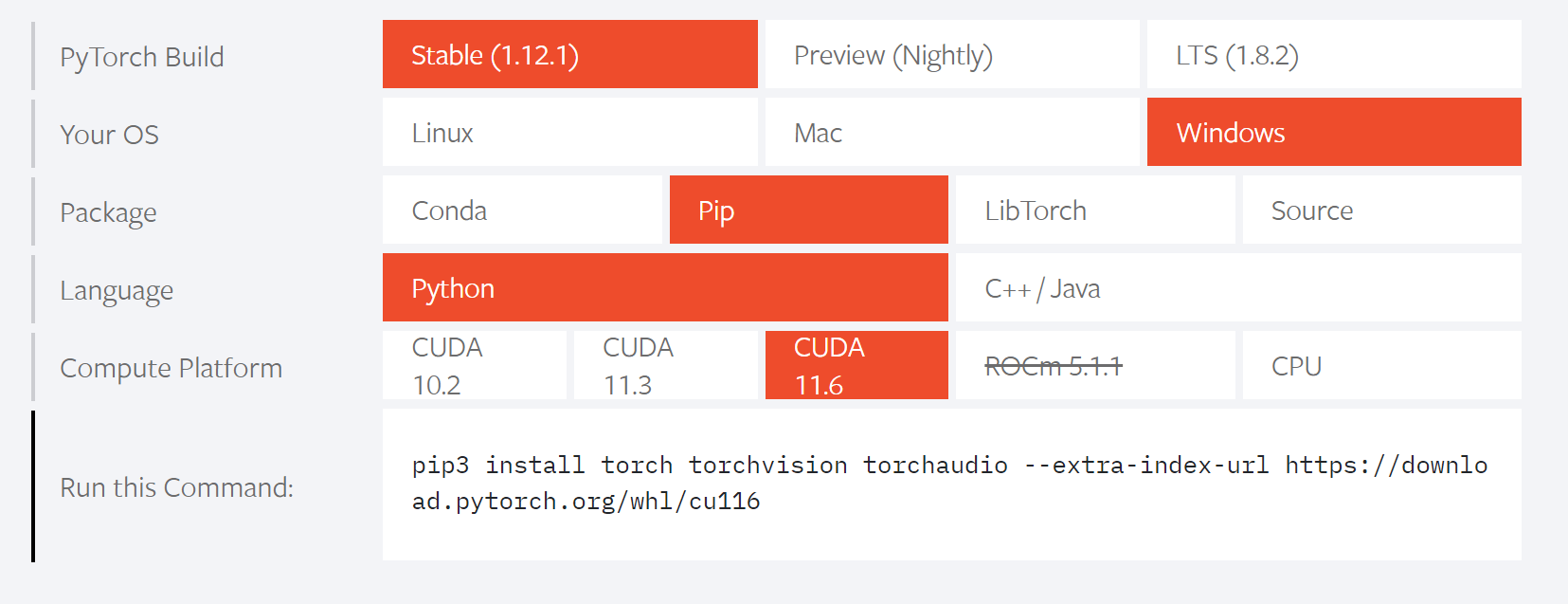
選択が完了したら、一番下の「Run this Command」欄にコマンドが表示されるので、これをコピー。
Windowsのコマンドプロンプトを起動して、貼り付けてEnterキーで実行します。

「PyTorch」のインストールが始まりますので、完了するまでしばらく待ちます。
続いて、インストールしたPyTorchでGPUを使用できるかどうか確認してみましょう。Windowsのコマンドプロンプトに
pythonと入力してEnterキーを押すと、「Python」が起動します(もし起動しなかったらPythonの再インストールを試してみてください)続けて、
import torchと入力してEnterキー。何もエラーが表示されなければ、続けて
torch.cuda.is_available()と入力してEnterキーを押します。「True」が表示されれば、PyTorchでGPUを使用する準備ができています。コマンドプロンプトは一旦閉じておいてください。
「Stable Diffusion」のセットアップ
ここからは、実際に「Stable Diffusion」を使えるように準備していきましょう。
Windowsのコマンドプロンプトを管理者権限で起動してください(Windows11の場合は、コマンドプロンプトを起動する前に右クリックすると「管理者として実行」が選択できます)
管理者権限で起動できたら、以下のコマンドをコピペします。
pip install diffusers==0.2.4 transformers scipy ftfy
Enterキーを押すと、必要なものが次々とインストールされます。
この作業は1回だけ行えばOKです。
「Stable Diffusion」で画像を生成する
いよいよ、Stable Diffusionで画像を生成してみましょう。
まずはGPUを使って画像生成するための準備をします。Windowsのコマンドプロンプトに
python
import torch
from torch import autocast
from diffusers import StableDiffusionPipelineと入力していきます。上記のコマンドは1行毎にEnterキーを押して、処理が終わるのを待ってから次の行に進んでくださいね。
続いて、トレーニング済みの重みをロードします。
筆者のGPUはメモリが10GB以下なので、デフォルトのfloat32精度ではなく、float16精度でロードします。以下のコマンドを入力してください。
なお、最後の「YOUR_TOKEN」の部分は「Hugging Face」で作成したアクセストークンに置き換えてください。
アクセストークンは「Hugging Face」アカウントページ「Settings」の「Access Tokens」からコピペできます。
pipe = StableDiffusionPipeline.from_pretrained("CompVis/stable-diffusion-v1-4", revision="fp16", torch_dtype=torch.float16, use_auth_token="YOUR_TOKEN").to("cuda")プロンプトを定義して画像を生成する
続いて、画像生成をするための文章(プロンプト)を定義して、実際に画像を生成します。
以下のコマンドの「プロンプト」の部分が、画像の元になる文章です。ここを自由に英文で書き換えてください。
text = "プロンプト"
with autocast("cuda"):image = pipe(text)["sample"][0]入力後にEnterキーを2回押す必要がある点にご注意ください。
画像が生成されるまでしばらく待ちます。処理が完了したら、画像の生成は完了です!
生成した画像をファイルに保存する
このままでは生成した画像を見る事も使う事もできませんので、生成した画像をファイルに保存してみましょう(ここでは、後でプロンプトを確認できるように、ファイル名=プロンプトとします)
image.save("{}.png".format(text))上記のコマンドを実行すると、カレントディレクトリに画像が保存されます(カレントディレクトリ移動などの操作を行っていない場合は、おそらくご自身のユーザーフォルダ「C:\Users\ユーザー名」がカレントディレクトリです)
保存する画像ファイルの拡張子は「.jpg」を使う事もできます。jpg形式なら保存容量をかなり減らせます。
一度に複数のバリエーションを生成する
上記までで画像の生成は可能になりましたが、同じプロンプトから複数の画像のバリエーションを生成する方法もご紹介しておきます。
以下のコマンドの「プロンプト」の部分を文章に、「生成したい数」を数値に書き換えてください。
text = "プロンプト"
num = 生成したい数
for i in range(num):
with autocast("cuda"):image = pipe(text)["sample"][0]
image.save("{}_{}.png".format(text,i))上記のコマンドを実行すると、カレントディレクトリに複数の画像が保存されます。
「for i in range(num):」以降の行は、最初にスペースを付けてインデントする必要がありますのでご注意ください。
幅と高さの指定
画像を生成する時に、パラメータを指定して出力画像を調整する事ができます。
with autocast("cuda"):image = pipe(text, width=512, height=512)["sample"][0]サイズは64の倍数で指定し、どちらか片方は512に固定する事が推奨されています。また、512以下を指定すると画質が低下するようです。
筆者のPC環境(GPUメモリ8G)では512を超える画像は生成できませんでした。大人しくデフォルト値を使用するしか無いかもしれません。